¡Atención, futuros diseñadores! Dejen de llorar frente a su hoja de cálculo. Creen que visualizar es darle a 'Insertar gráfico' y ya está. Pucha, qué inocentes. Visualizar es hacer que la información entre por los ojos y se transforme en comprensión dentro de la cabeza.
El caso John Snow: cuando la visualización salvó vidas

¡Atención, futuros diseñadores! Dejen de llorar frente a su hoja de cálculo. Creen que visualizar es darle a 'Insertar gráfico' y ya está. Pucha, qué inocentes. Visualizar es hacer que la información entre por los ojos y se transforme en comprensión dentro de la cabeza.
Caso de John Snow (1854)
John Snow, un médico británico, es conocido por su trabajo durante la epidemia de cólera en Londres en 1854. Snow sospechaba que el cólera se transmitía a través del agua contaminada, en contraposición a la teoría predominante de la época que atribuía la causa de la enfermedad al aire malo. Para demostrar su teoría, Snow creó un mapa de Londres en el que marcó las ubicaciones de las viviendas de las personas que habían muerto de cólera. Al analizar la distribución de los casos, notó una alta concentración de muertes alrededor de una bomba de agua específica en Broad Street (hoy Broadwick Street). El mapa (Fig. 1.1) no solo mostraba los casos de cólera, sino que también ayudaba a visualizar un patrón claro que indicaba la fuente de la epidemia. Gracias a esa visualización, Snow logró convencer a las autoridades para que retiraran la manivela de la bomba, interrumpiendo así la epidemia. Este caso es un ejemplo pionero de epidemiología moderna y demuestra cómo la visualización de datos puede revelar información crucial para la salud pública.

Caso de Florence Nightingale (1858)
Florence Nightingale, una enfermera británica, es famosa no solo por su trabajo de enfermería durante la Guerra de Crimea, sino también por su contribución al uso de la estadística y la visualización de datos para mejorar las condiciones sanitarias. Nightingale utilizó un tipo de gráfico de tarta modificado, conocido como “diagrama de rosa” o “coxcomb chart” (Fig. 1.2), para ilustrar las causas de mortalidad de los soldados durante la guerra. A través de este gráfico, Nightingale mostró que un número significativo de muertes se debía a enfermedades prevenibles en lugar de a heridas de guerra. El trabajo de Nightingale condujo a una mayor conciencia de la importancia de las condiciones higiénicas en los hospitales y estimuló reformas sanitarias que salvaron innumerables vidas. Su uso innovador de la visualización de datos demostró cómo la información compleja podía presentarse de manera clara y persuasiva para promover cambios significativos.

El Cuarteto de Anscombe: cuando las estadísticas mienten y los gráficos delatan

Hay un cuarteto famoso para el que aprende y desconfía, cuatro grupos de datos que van a hipnotizarte un día. Tienen la misma media, la misma desviación, la misma correlación... pero si los graficas, son completamente extraños.
El Cuarteto de Anscombe
El Cuarteto de Anscombe es un conjunto de cuatro conjuntos de datos que, como se ve en Fig. 2.1, tienen las mismas propiedades estadísticas (media, varianza, correlación, y línea de regresión), pero que son claramente diferentes cuando se visualizan en un gráfico.

Este cuarteto fue creado por el estadístico Francis Anscombe para demostrar la importancia de visualizar los datos antes de analizarlos. Cada conjunto de datos en el cuarteto de Anscombe parece ser similar cuando se examinan sus estadísticas resumidas, pero al graficarlos (Fig. 2.2) aparecen diferencias significativas entre los conjuntos de datos, lo que subraya la importancia de la visualización de datos en el análisis estadístico.

Correlación en el Cuarteto de Anscombe
La correlación es un concepto estadístico que describe cómo dos variables se mueven juntas. En términos sencillos, la correlación nos dice si existe una relación entre dos cosas y cuán fuerte es esa relación.
Existen tres tipos de correlación:
- Correlación Positiva: Cuando una variable aumenta, la otra tiende a aumentar. Por ejemplo, cuanto más estudias, más altas son las calificaciones que obtienes.
- Correlación Negativa: Cuando una variable aumenta, la otra tiende a disminuir. Por ejemplo, cuanto más calor hace, menos se venden las bebidas calientes.
- Ninguna Correlación: Cuando las variaciones de una variable no influyen en la otra. Por ejemplo, el número de zapatos que posees no tiene relación con el número de libros que lees.
Un scatter plot es un gráfico que utiliza puntos para representar los datos (ver Cuarteto de Anscombe). Cada punto muestra una observación para dos variables. Cuando hablamos de correlación en los scatter plots, a menudo se dibuja una línea llamada “línea de tendencia” o “línea de regresión” para ayudar a visualizar la relación entre las variables.
La línea de regresión es una línea recta que mejor se aproxima a los datos en el gráfico. Aquí está lo que representa:
- Si la línea sube hacia la derecha: indica una correlación positiva (cuando una variable aumenta, la otra también aumenta).
- Si la línea baja hacia la derecha: indica una correlación negativa (cuando una variable aumenta, la otra disminuye).
- Si la línea es plana: indica que no hay correlación entre las variables (los cambios en una variable no influyen en la otra).
La línea de regresión ayuda a ver rápidamente si existe una relación y cuán fuerte es esa relación.
T0. La web esencial: HTML, CSS, DOM, JavaScript y eventos
Lo mínimo del navegador para hacer infovis. Cinco demos en vivo + enlaces a MDN.
El navegador es la imprenta del siglo XXI. Lo que tu computador dibuja en pantalla, lo dibuja todo desde tres archivos de texto: un HTML, un CSS y un JavaScript. Esta cápsula te da el mapa mínimo para moverte en ese terreno antes de tocar Plotly.
¿Por qué empezar por la web?
Las visualizaciones que vamos a hacer en este curso —Plotly, mapas interactivos, sonificación, fisicalización— viven en el navegador. No en Photoshop, no en Tableau, no en un PDF. Hay tres razones:
- Llegan a cualquier dispositivo sin que nadie tenga que instalar nada. Un link, y se ve en móvil, en tableta, en el proyector del aula, en la pantalla de un quiosco.
- Son interactivas por defecto. El navegador ya entiende clics, toques, teclas, sensores. No tienes que "agregar" interacción — tienes que decidir cuál usar.
- El código fuente está a la vista (View Source). Eso es enorme pedagógicamente: cada visualización del curso —y de la web— se puede diseccionar abriendo Inspeccionar elemento. Aprendes leyendo.
Antes de hacer un gráfico necesitas saber qué le pasa al navegador cuando carga una página. Eso es lo que vamos a ver acá, en cinco demos cortos.
Antes de seguir. Esta cápsula no pretende enseñar a programar. Pretende darte el vocabulario mínimo para entender los próximos capítulos y para poder preguntarle a un LLM (ChatGPT, Claude, Gemini…) cosas como "hazme una barra Plotly con un click que dispare un sonido". Si una sección te queda corta, pégasela al LLM y pídele un ejemplo más largo. Es la forma más rápida hoy de profundizar.
1 · HTML — estructura semántica
El HTML no es "el texto de la página". Es un árbol etiquetado que
describe el rol de cada parte. <h1> es un título principal,
<p> un párrafo, <ul> una lista, <a> un enlace.
El navegador lee ese árbol y le da un estilo por defecto: títulos en grande, listas indentadas, enlaces en azul. Pero lo importante no es el estilo — es que las etiquetas tienen significado: un lector de pantalla, un buscador, una IA, todos entienden lo que tienen delante porque los nombres son semánticos.
📚 La misma receta escrita con tags semánticos — `<h1>`, `<ul>`, `<blockquote>`. Sin estilos, ya se lee como un documento.
Etiquetas que vas a usar el 90% del tiempo: <h1> a <h6> (títulos),
<p> (párrafo), <ul>/<ol>/<li> (listas), <a href> (enlace),
<img src> (imagen), <div> (caja genérica), <span> (trozo de texto
genérico), <button> (botón).
Referencia completa: MDN · HTML element reference.
2 · CSS — estilos separados del contenido
CSS asigna estilos visuales al HTML a través de selectores. La idea es brutal: el HTML describe qué hay, el CSS describe cómo se ve. Si cambias el CSS, cambia la apariencia sin tocar el contenido.
Reglas básicas:
h1 { color: #c8442a; font-size: 2rem; } /* por etiqueta */
.destacado { background: yellow; } /* por clase */
#titulo { font-weight: 700; } /* por id */
.btn:hover { background: red; } /* estado pseudo-clase */
📚 Mismos `<h1>`, `<p>`, `<a>` — al pulsar "Neón" cambia solo el CSS y la página se transforma.
CSS también gobierna layout (flex, grid), tipografía, transiciones, animaciones y responsive design (medidas distintas según el ancho de la pantalla). Es enorme. Para infovis lo que importa al inicio: colores, tamaños, espaciado, y entender que cambiar un color de una viz nunca debería implicar tocar el HTML.
Referencia: MDN · CSS reference. Para empezar: Aprende CSS · MDN.
3 · DOM — el árbol vivo
Cuando el navegador termina de leer el HTML, lo convierte en un objeto JavaScript que se llama DOM (Document Object Model). Cada etiqueta es un nodo, cada atributo una propiedad. Y el DOM se puede modificar en vivo: agregar nodos, cambiar texto, mover cosas.
JavaScript habla con el DOM con tres verbos centrales:
// 1) ENCONTRAR un nodo (un solo elemento o varios)
const tit = document.querySelector('#titulo'); // por selector CSS
const items = document.querySelectorAll('.item'); // lista de todos
// 2) CAMBIAR su contenido o sus atributos
tit.textContent = 'Otro texto';
tit.style.color = 'red';
tit.classList.add('activo');
// 3) CREAR y AGREGAR nodos nuevos
const nuevo = document.createElement('li');
nuevo.textContent = 'creado en vivo';
document.querySelector('#lista').appendChild(nuevo);
📚 Cada botón corre 2-3 líneas de JS que tocan el DOM. Una infovis dinámica es exactamente esto, repetido muchas veces con datos.
Referencia: MDN · DOM.
4 · Eventos — la página escucha al usuario
Un evento es algo que pasa: un click, el mouse que entra en una
zona, una tecla apretada, una imagen que termina de cargar.
JavaScript se "suscribe" con .addEventListener('nombre', funcion):
boton.addEventListener('click', () => {
console.log('me apretaste');
});
input.addEventListener('input', e => {
console.log('escribiste:', e.target.value);
});
document.addEventListener('keydown', e => {
console.log('tecla:', e.key);
});
📚 Cuatro paneles con cuatro eventos típicos. Toda interacción del curso se construye combinando estos pocos.
Eventos más usados en infovis: click, mouseenter/mouseleave
(hover), input/change (controles), keydown/keyup (teclado),
y los específicos de librerías (Plotly tiene plotly_hover,
plotly_click, etc.).
Referencia: MDN · Event reference.
5 · Todo junto — una mini-InfoVis
Hasta acá los demos eran texto y botones. Una visualización suma
una pieza más: gráficos vectoriales (<svg>), dibujados a partir
de un array de datos, con eventos atados a cada elemento.
const datos = [12, 18, 14, 20, 15, 22];
datos.forEach((v, i) => {
const r = document.createElementNS('http://www.w3.org/2000/svg', 'rect');
r.setAttribute('x', i * 50);
r.setAttribute('y', 100 - v);
r.setAttribute('width', 40);
r.setAttribute('height', v);
r.addEventListener('mouseenter', () => console.log('barra', i, ':', v));
svg.appendChild(r);
});
📚 Filtros (botones), hover (resalta la barra), click (muestra el desglose). Cinco demos resumidos en uno.
Esto es una visualización web — barras SVG dibujadas desde un array, con filtros y tooltips. Cuando lleguemos a Plotly (T1) ya no vamos a dibujar las barras a mano: la librería lo hace. Pero el mecanismo subyacente es exactamente este.
¿Y ahora qué?
No tienes que memorizar nada de esta cápsula. Tienes que saber que existe y poder buscarlo cuando lo necesites.
Estrategia recomendada:
- MDN (developer.mozilla.org) es la referencia oficial — siempre actualizada, ejemplos sólidos, en español. Guárdalo en favoritos.
- LLMs (ChatGPT, Claude, Gemini) son excelentes para "dame un ejemplo mínimo de Y", "explícame qué hace este código", "refactoriza este HTML". Úsalos como tutor 1-a-1. Pega el código que tienes y pregunta sin miedo.
- Inspeccionar elemento (F12 en cualquier navegador). Abre la consola, mira el DOM de cualquier página web, juega con los estilos. La web está abierta — aprovéchalo.
Con eso ya tienes el mapa. En la próxima cápsula técnica (T1) empezamos a usar Plotly para hacer un gráfico estático real con datos reales.
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Qué significa visualizar: visión, oído, tacto y la fuerza de la imagen

¡Despierten, genios! ¿Creen que visualizar es solo 'ver'? Visualizar es algo más sutil: es hacer que tu cerebro forme una imagen y que esa imagen te diga algo. Cuando entiendes y dices 'ya veo, ya cachái', estás visualizando.
¿Qué significa visualizar?
La visualización es quizás más fácil de reconocer que de definir. En el libro “Visualización de Información”, Bob Spence se refiere a la definición del diccionario: visualizar: formar un modelo mental o una imagen mental de algo. Él enfatiza que la visualización es críticamente acerca de la perspicacia, lo que sucede en tu cabeza, no en una computadora. Alan Dix adopta una definición ligeramente diferente de visualización (de información): hacer que los datos sean más fáciles de entender utilizando la experiencia sensorial directa.
Esta definición sigue siendo sobre perspicacia y comprensión, pero también sobre la percepción (‘experiencia sensorial’) y el diseño deliberado (‘haciendo’). También esta definición dice ‘sensorial’, no simplemente ‘visual’, ya que la visualización interna que te hace decir “Veo” también puede ser engendrada por otros sentidos.
Aunque menos comunes, también existen formas de visualización auditiva y táctil. La comparación entre canales sensoriales (Fig. 4.1) muestra que la vista procesa mucha más información por unidad de tiempo que el oído o el tacto, pero esos canales también transmiten datos.

Empecemos por el oído: usar el sonido para representar datos se llama sonificación. En un contador Geiger (Fig. 4.2) el ritmo de los clics indica el nivel de radiación — clics más rápidos significan mayor radiación. El mismo principio aparece en los sensores de estacionamiento (Fig. 4.3): la frecuencia de los pitidos aumenta a medida que el parachoques se acerca al obstáculo, y un tono continuo significa "frena ya" — justamente útil cuando los ojos están ocupados en la maniobra.
Sigamos con el tacto: representar datos a través de formas físicas que se pueden tocar se llama fisicalización. De manera táctil, por ejemplo, podrías percibir la intensidad de la velocidad al tocar el borde de una rueda que gira (Fig. 4.4). Estas formas no visuales son particularmente valiosas para quienes tienen discapacidad visual, pero también en cualquier contexto en el que los ojos necesitan estar en otro lugar. Dicho esto, la gran mayoría de la visualización es, como sugiere el nombre, visual: la corteza visual representa alrededor del 50 % de nuestro cerebro, así que tiene sentido apoyarse en ella.

(Volveremos sobre la sonificación y la fisicalización en profundidad más adelante en el curso — por ahora basta saber que la visualización no termina en los ojos.)
¿A qué se dedica la InfoVis?
¿Cómo deberíamos llamar a la Visualización de Información en la compleja articulación del concepto de Ciencia de Datos? Esta pregunta es muy afín a preguntarse: ¿qué significa visualizar los datos? Ciertamente no podemos limitarnos a pensar que se trata de “hacer visibles” los datos, es decir, simplemente hacerlos disponibles a nuestra vista. Incluso imprimir datos en forma textual y simbólica entre los estrechos márgenes de una tabla equivaldría a hacerlos visibles; pero hacerlo como propuesta de una “visualización de datos” parecería más una provocación que una ejemplificación correcta. En realidad, ocuparse de la visualización de datos significa concebir, diseñar, realizar y validar modalidades oportunas y adecuadas para hacer que los datos sean visuales, o mejor, más visuales (Cabitza, 2020).
Visualizando números
Esto no significa que el texto y los números no sean parte integral de la visualización. Un buen diseño puede crear impresiones visuales (u otras sensoriales) directas.
🎲 Hagamos un juego. Para entender qué significa hacer los datos más visuales, lo mejor es experimentarlo en carne propia. En las próximas tres figuras te pediré una sola cosa: identificar, lo más rápido posible, cuál es el número más grande de una columna. Fíjate en lo que te cuesta cada intento — vas a notar que la velocidad cambia drásticamente según cómo estén presentados exactamente los mismos números.
Primer intento (Fig. 4.5): ¿cuál es el número más grande?

¿Cuánto tardaste? Probablemente tuviste que leer cada número dígito por dígito y compararlos mentalmente.
Segundo intento (Fig. 4.6): la misma pregunta, otra columna.

Mucho más rápido, ¿verdad? La razón es que los números de esta segunda columna tienen sus puntos decimales alineados, así que los más grandes son también los que más sobresalen a la izquierda del punto decimal. Efectivamente, la línea de cifras actúa como un gráfico de barras en miniatura: cada parte entera es una pequeña barra, y su longitud te dice la magnitud sin que tengas que leer un solo dígito.
De hecho, si hacemos las barras explícitas (Fig. 4.7), queda claro que la línea de cifras es un gráfico de barras.

¿Qué significa hacer los datos "más visuales"?
Entonces, ¿qué significa hacer los datos "más visuales"? Podemos intentar traducirlo en términos simples y después complicar un poco el asunto. Por ahora basta con decir: significa darles una fuerza comunicativa que "habla" también a través de elementos gráficos, imágenes, formas, colores, y por alguna semejanza y cercanía a la "cosa real" u observable, y a las magnitudes a las que los datos quieren referirse o de las que son medida. Un buen ejemplo (Fig. 4.8, Ware, 2019) es la visualización del peso y la altura de 396 personas mediante óvalos más o menos anchos y largos: cada óvalo codifica simultáneamente dos magnitudes en su forma.

Visualizar los datos significa, por lo tanto, mostrarlos, ilustrarlos, exponerlos — en contraposición a hablar de ellos y describirlos con palabras.
Giro visual
El giro visual (visual turn) es el término con el que se denota un nuevo y relativamente reciente gran interés por parte de un número creciente de estudiosos en las ciencias humanas y sociales por todas las formas visuales (y no escritas) que habitan y caracterizan nuestra cultura contemporánea (así como muchas otras culturas, incluyendo muchas de las llamadas “tradicionales”). Desde principios del siglo XXI, los estudios se han centrado en el papel de los artefactos y productos visuales, así como en la importancia de las correspondientes prácticas de producción y consumo para comprender las culturas y sociedades que se caracterizan por ellos. Se observa cómo la tecnología de la segunda mitad del siglo XX ha introducido en nuestra vida una presencia cada vez mayor y más atractiva de formas visuales. Estas formas visuales tienen el propósito de representar los hechos, lo que sabemos del mundo que nos rodea, y contar nuevas historias, o de manera más persuasiva y poderosa, sobre el mundo que habitamos.
Algunos ejemplos de esta influencia son:
- Cine y Televisión: Estos medios han revolucionado la forma en que consumimos historias y nos informamos, convirtiéndose en una parte integral de nuestra vida cotidiana.
- Publicidad en Televisión: La publicidad televisiva ha influido en gran medida en nuestras decisiones de consumo y ha moldeado la cultura popular.
- Impresión Offset en Periódicos y Revistas: Esta innovación ha permitido la producción masiva de material impreso, facilitando la difusión de información.
- Videojuegos: Los videojuegos han emergido como una nueva forma de entretenimiento y narrativa, con un impacto significativo en la cultura popular.
- Computación Personal: La transición de los terminales de caracteres a las interfaces visuales, como las “ventanas”, los escritorios (“desktop”) y los iconos que indican tanto objetos metafóricos (por ejemplo, carpetas y documentos) como operaciones sobre ellos (como “guardar” y “cortar”), ha revolucionado la forma en que interactuamos con la tecnología.
Estos avances tecnológicos han cambiado profundamente nuestra relación con el mundo visual y han tenido un impacto significativo en nuestra sociedad y cultura. A medida que continuamos avanzando en el siglo XXI, es probable que veamos aún más innovaciones y cambios en este ámbito.
Texto vs. imagen: la velocidad de la comprensión
¿Por qué tanta importancia a lo visual? Porque procesamos imágenes mucho más rápido que las palabras. Hagamos la prueba en concreto. Te muestro la misma información dos veces — primero como texto, después como visualización. La pregunta es simple: ¿cuánto tardas en "cachar" en cada caso?
Ejemplo 1 — ¿Qué tipo de hogar ganó más?
📖 Veamos la fuerza de la visualización. Te voy a dar la misma información de dos maneras. Primero, en texto. Lee con atención el párrafo siguiente y responde: ¿qué tipo de hogar tuvo el mayor crecimiento de ingresos entre 2014 y 2015? Vas a notar que, para contestar, hay que leerlo casi entero y retener tres cifras a la vez.
Este es el texto, publicado por Vox en 2016:
El censo contó más de 20 millones de hogares ubicados fuera de cualquier área metropolitana — es decir, en zonas rurales — y encontró que estos hogares vieron sus ingresos caer un 2 % entre 2014 y 2015: de $45.534 a $44.657.
Había 63 millones de hogares dentro de áreas metropolitanas pero fuera de la ciudad principal — es decir, en los suburbios. Estos hogares disfrutaron de un saludable crecimiento del 4 %, pasando de los ya altos $61.671 a $64.144.
Pero las mayores ganancias correspondieron a los 41 millones de hogares ubicados en la ciudad principal de un área metropolitana. Sus ingresos crecieron un impresionante 7,3 %, pasando de $47.095 a $51.378.
— Vox (2016)
Ahora mira el mismo contenido representado como gráfico (Fig. 4.9):

¿Cuánto tardaste en darte cuenta de que los hogares urbanos fueron los que más crecieron? En el texto, había que leer tres párrafos, retener cifras y compararlas mentalmente. En el gráfico, la línea más empinada salta a la vista en menos de un segundo. La misma información — distinta velocidad de comprensión.
Ejemplo 2 — Cómo salir del edificio en caso de incendio
🔥 Segundo experimento. Suena la alarma de incendios y tienes que salir del edificio ahora. Tus instrucciones están abajo, en texto. Léelas, intenta memorizar el recorrido y averigua por dónde se sale — hazlo con la prisa que tendrías en una emergencia real, porque esa presión es parte del experimento.
Estas son las instrucciones de evacuación:
Sal de esta sala. Gira a la derecha y camina 3 metros hasta el final del pasillo, donde te encontrarás frente a una gran sala de conferencias. Gira a la izquierda y camina otros 3,6 metros hasta llegar al final de ese pasillo. A tu izquierda hay una alarma de incendios, cerca del ascensor. A tu derecha, al final del pasillo, hay una escalera. No vayas al ascensor. Gira a la derecha y camina otros 3,6 metros hasta el final del pasillo, gira a la izquierda y entra en la escalera. Baja dos pisos y sal del edificio por la puerta que hay al final de la escalera.
Bajo presión, leer y memorizar todo esto es casi imposible. Ahora mira la versión visual (Fig. 4.10):

El plano no te pide leer ni recordar nada: sigues la flecha. Esa es la fuerza de la visualización — convierte una secuencia de instrucciones en una forma que el cerebro procesa de inmediato.
Experto vs paciente: scatter plot denso o frecuencias naturales

Imaginen 2700 pacientes. Si les das una tabla inmensa, no van a entender nada. Hoy aprendemos a hablarle al experto (con un scatter plot denso) y al paciente (con frecuencias naturales claras).
Un caso práctico de visualización de información
🩺 Los datos de hoy. Vamos a trabajar con un caso real: 2.700 hombres a los que se les hizo un escáner óseo (DEXA) en Londres. De cada uno conocemos sólo dos cosas: su edad y su Índice de Masa Grasa (FMI) — una medida de cuánta grasa carga el cuerpo, más informativa que el simple peso, y clave para estimar el riesgo cardiovascular y metabólico.
En 2017, la empresa británica Bodyscan Limited publicó los datos de más de 2.700 de estas mineralometrías óseas computarizadas, realizadas en los dos años anteriores a sujetos masculinos en Londres. La exploración DEXA se usa generalmente para diagnosticar y evaluar la osteoporosis; aquí imaginamos que de cada examen hemos extraído únicamente los dos números que nos interesan: el FMI y la edad.
Tenemos entonces dos columnas de datos — ambas numéricas y cuantitativas — y nada más. Una tabla cruda con esos números (Fig. 5.1) sería tan densa que resultaría ilegible: nadie distingue un patrón en una lista de miles de filas. Es el primer escalón del problema — sin visualización no hay lectura — y la pregunta que abre la cápsula: ¿qué gráfico le doy a un experto y cuál a un paciente?

Lo que el ojo no entrenado ve (y lo que se le escapa)
👁️ Un reto antes de seguir. En la próxima figura verás a los mismos 2.700 pacientes como un scatter plot: cada punto es una persona — su edad en el eje horizontal, su FMI en el vertical. Mírala unos segundos y respóndete una pregunta: ¿hay una correlación entre la edad y la grasa corporal? Quédate con tu respuesta — la vamos a poner a prueba enseguida.
Ahí está el scatter plot (Fig. 5.2). La línea roja marca el FMI promedio del grupo, 5,78 kg/m².

¿Y bien? La mayoría de las personas dirá no: la nube parece equilibrada alrededor de la línea roja, sin una pendiente clara. Y aquí está la trampa de la cápsula — porque la correlación sí está ahí, sólo que escondida en una región concreta de la nube.
Mirando las nubes o enjambres de puntos que los gráficos de dispersión presentan a la vista, la persona experta en visualización "ve" más signos: la densidad global de la nube le habla de la numerosidad de la muestra, las regiones más densas le hablan de las modas, del valor medio y de la variabilidad alrededor de él. El ojo experto también vislumbra cómo se distribuyen los valores en cada dimensión y, por la simple forma de la nube — más o menos alargada — intuye la intensidad de la correlación entre las dos variables.
Hacer visible lo invisible: las dos zonas
¿No notaste la asimetría arriba de los 50 años? Mira ahora la misma nube con dos zonas resaltadas a la derecha del corte en 50 años (Fig. 5.3): arriba de la media en naranja, debajo en amarillo. La cuenta es brutal: 380 pacientes arriba y sólo 102 abajo. Hartos más puntos en la zona "alta" que en la "baja" — casi cuatro veces.

Eso es exactamente lo que la empresa Bodyscan describió en su informe: "hay una tendencia en los datos desde abajo a la izquierda hacia arriba a la derecha — los pacientes acumulan grasa con la edad — pero la tendencia es ligera y parece estar ausente hasta la mitad de los 50 años; después de los 60 casi todos los pacientes tienen un FMI superior, y también mucho superior, al valor mediano". El gráfico no cambió: los puntos son los mismos. Lo que cambió fue dónde miramos.
La prueba final: aislar al subgrupo
Y si necesitamos prueba definitiva, basta con quedarnos sólo con los mayores de 50 años (Fig. 5.4). Los demás puntos quedan como fantasmas grises, y sobre el subgrupo aparece la diagonal de tendencia: r = 0,40. Una correlación moderada y nítida, imposible de pasar por alto.

Aquí está la lección para el lector: el experto en visualización no necesita el subgrupo aislado para ver la correlación. Se le revela ya en la primera nube — por la asimetría de las densidades, por la forma de la "espuma" en el extremo derecho. Donde el ojo común ve una nube tranquila, el ojo entrenado huele el humo y reconoce el incendio. No es magia ni superioridad: es práctica. Cuando uno ha visto cientos de scatters, las modas, las colas y las regiones densas dejan de ser ruido y se vuelven signos.
Hablarle al paciente: frecuencias naturales
💬 Cambiemos de interlocutor. Todo lo que hicimos hasta aquí — leer densidades, aislar subgrupos, calcular un r — funciona para un experto. Pero un paciente (o el médico apurado, o el periodista que cita el estudio) no va a leer una nube de 2.700 puntos. La pregunta cambia: ¿cómo le mostramos exactamente el mismo hallazgo de una forma que entienda en un segundo?
Para esas audiencias existen gráficos donde no operan signos indicativos sino icónicos. Este tipo de visualización se difunde desde que se observó que razonar por "frecuencias naturales" — en términos de números del 1 al 100, no porcentajes abstractos — es más natural y fácil, especialmente para usuarios no expertos como los pacientes. A pesar de su utilidad este diagrama aún no tiene un nombre consolidado en la literatura, aunque algunos lo llaman pictorial fraction chart.
Un buen ejemplo es la versión "para paciente" del mismo dato (Fig. 5.5): de cada 100 pacientes mayores de 50 años, 35 tienen un FMI superior a 7 kg/m² — el umbral del riesgo de síndrome metabólico. La porción de rojo y la composición de la figura indican al instante "cuántos sí, cuántos no". El símbolo del hombre es aquí el signo icónico que sugiere la idea de probabilidad en sus términos más elementales — numerosidad — y el rojo se vuelve el índice que señala riesgo. Es fácilmente comprensible y probablemente más efectivo para comunicar y persuadir al paciente. Los expertos, en cambio — los científicos de datos — preferirán (¡tal vez!) la nube del scatter, donde caben todas las lecturas que vimos en las figuras anteriores.

Mismo dato, dos audiencias, dos gráficos. La cápsula no enseña a elegir uno por encima del otro; enseña a decidir cuál sirve en cada conversación.
El contexto manda: audiencia, narrativa y puntos de vista en InfoVis

¡Acomódense! Piensan que un gráfico flota en el vacío, puro, inmaculado... ¡Falso! Sin contexto, sus datos son solo píxeles desperdiciados. Todo depende de la ventana por la que elijas mirar.
¿Qué es el contexto?
El contexto es un concepto clave que se refiere a los distintos entornos que influyen en la interpretación y comprensión de un hecho o una expresión. Según la Real Academia Española (RAE), el contexto puede entenderse desde dos perspectivas principales. Primero, como el “entorno lingüístico del que depende el sentido de una palabra, frase o fragmento determinados”. Esto implica que el significado de un término o enunciado puede variar significativamente según las palabras y oraciones que lo rodean. En segundo lugar, el contexto también abarca el “entorno físico o de situación”, incluyendo aspectos “políticos, históricos, culturales o de cualquier otra índole en el que se considera un hecho”. En otras palabras, para comprender plenamente un acontecimiento o expresión, es esencial tener en cuenta tanto el marco lingüístico en el que se presenta como las circunstancias externas que lo rodean.
Esta visualización (Fig. 6.1) lo resume: el «hecho» en el centro, rodeado de las seis preguntas (quién, qué, cuándo, dónde, por qué, cómo) que lo contextualizan. Sin esas respuestas, el hecho está incompleto — y un gráfico que ignora alguna de ellas comunica menos de lo que cree.

En términos lingüísticos, podemos utilizar un tipo de visualización llamado "Key Word in Context" (Fig. 6.2), que nos facilita la comprensión del contexto de una palabra o conjunto de palabras al mostrarlas alineadas con sus concordancias a izquierda y derecha.

El uso de las palabras depende del contexto. Una palabra o un conjunto de palabras puede asumir diferentes significados según las palabras que las rodean. Este concepto se extiende claramente a la segunda definición propuesta por la RAE, donde el contexto no se limita solo al texto escrito, sino que incluye todo el entorno que nos rodea.
Entre InfoVis, Infografías, Humor y DataArt
Durante el proceso de diseño de una visualización de información, es crucial comprender a quién nos dirigimos. Cuanto más específica sea la definición de la audiencia, más efectivo será el diseño. Un diseño que funciona bien para expertos en datos o personas con antecedentes científicos puede no ser igualmente adecuado para consumidores comunes de datos. Es importante adaptar la visualización a las necesidades y conocimientos del público objetivo, lo que a veces puede implicar crear diferentes versiones de la misma visualización para audiencias distintas. También, el objetivo de diferentes visualizaciones puede variar; no solo pueden estar destinadas a explorar e informar, sino también a emocionar, entretener, entre otros propósitos.
En particular, se suele distinguir entre infografías y visualizaciones de datos (DataVis/InfoVis). Aunque la distinción no es rígida y debe verse como un continuum (Fig. 6.3), se pueden observar características distintivas en ambos tipos, como se muestra a continuación:

| Infografía / DataArt | DataVis / InfoVis |
|---|---|
| Público no técnico. Accesible para una audiencia amplia, sin formación técnica. | Público experto. Pensada para analistas, científicos, investigadores. |
| Narrativa, estética, síntesis. Combina texto e imágenes para contar una historia visualmente atractiva. | Precisión por encima de todo. Puntos, líneas, barras, mapas — signos gráficos exactos para datos detallados. |
| Inmediata. Se entiende a primera vista, sin análisis profundo. | Requiere esfuerzo cognitivo. El lector tiene que invertir tiempo para extraer los patrones. |
| Enfocada en explicar. El propósito es comunicar un mensaje (emocionar, entretener, persuadir). | Enfocada en explorar. Permite descubrir patrones, tendencias y relaciones en grandes conjuntos de datos. |
| Puede incluir elementos de InfoVis para reforzar la claridad. | Integra técnicas avanzadas de visualización; es InfoVis en sentido estricto. |
Al diseñar visualizaciones, es esencial considerar el contexto y la audiencia objetivo. Mientras que las infografías y data art buscan simplificar, comunicar de manera atractiva, entretener y/o emocionar, las visualizaciones de datos profundizan en el análisis y la exploración, cada una jugando un papel crucial en la comunicación de información según el propósito y el público destinatario.
Navegando en el continuum
El continuum InfoVis–Infografía no es una clasificación rígida sino un mapa de propósitos. Cada propósito redefine qué se espera del gráfico y qué criterios tienen sentido para evaluarlo:
- Analizar y explorar — visualizaciones que ayudan a descubrir patrones, identificar tendencias y formular hipótesis. Aquí el contexto es crucial para no perderse en la abundancia ni saltar a conclusiones equivocadas.
- Infografías y presentaciones — explican un concepto o dato con un propósito específico (educar, persuadir, informar). El contexto garantiza que el mensaje llegue a la audiencia sin ambigüedad.
- Contar historias (storytelling con datos) — guían a la audiencia a través de una narrativa donde los datos son apoyo, no protagonista. Sin contexto, la narrativa se pierde.
- Humor — usan el dato como vehículo de un chiste. Acá el contexto es vital para que el chiste funcione y para que no se lea como un error.
- Data Art — usan los datos como medio estético y expresivo. El contexto puede ser más interpretativo, pero sigue siendo necesario para que la audiencia conecte con la intención del autor.
La conclusión práctica: no se puede evaluar todas las visualizaciones con los mismos criterios. Una visualización científica se juzga por precisión y eficiencia; una humorística por agudeza; un data art por resonancia emocional. Antes de aplicar una regla, conviene preguntarse en qué punto del continuum vive el gráfico y qué se le está pidiendo.
Una colección de ejemplos — varios por cada punto del continuum — fija visualmente lo que separa estos propósitos: Galería 6.1
Galería 6.1: El continuum InfoVis ↔ Infografía en imágenes
Una serie de ejemplos que recorren los cinco propósitos del continuum — análisis y exploración, infografía, storytelling, humor y data-art — ordenados del más analítico al más expresivo. La misma idea de "visualizar datos" produce artefactos radicalmente distintos según el propósito que se tenga en mente.








El extremo expresivo del continuum — el data-art — vive necesariamente en movimiento. Aquí está "Forms" del National Media Museum, que traduce el movimiento de atletas olímpicos en esculturas dinámicas: (Fig. 6.4).
Contar historias
🪟 Un mismo dato, dos historias. Lo que el contexto deja brutalmente claro es esto: la misma serie de números puede sostener conclusiones opuestas según qué ventana elijas para mirarla. En los próximos ejemplos vas a ver el mismo dato presentado de dos maneras — y cada vez vas a "entender" algo distinto. La pregunta nunca es cuál versión es la verdadera, sino quién eligió la ventana, y para qué.
Pensemos en el interés por los vinilos (Fig. 6.5). Si graficas la curva entre 1993 y 2014, se ve un alza nítida y reciente —dirías que el vinilo "está volviendo". Si en cambio extiendes el eje a 1973-2014, la misma serie cae en picado y dirías que el vinilo "está muerto". Las dos lecturas son técnicamente correctas; lo que cambió es la ventana temporal. Una empresa de vinilos prefiere la primera, una plataforma de streaming prefiere la segunda. Misma curva, dos relatos comerciales opuestos.

💰 ¿Qué quieres saber, exactamente? El próximo ejemplo es distinto al del vinilo: aquí nadie manipula nada. Tienes los precios del oro y la plata, y dos gráficos posibles. Antes de mirarlos, decide tu pregunta — porque no son la misma: ¿quieres saber cómo evoluciona el precio de cada metal, o cuál de los dos es más inestable? Cada pregunta tiene su propio gráfico correcto.
El punto de vista numérico es otra ventana que cambia la lectura. Mira los dos gráficos (Fig. 6.6). El de la izquierda — de dos ejes Y — responde muy bien a la primera pregunta: con cada metal en su propia escala, ves con claridad cómo sube y baja el precio absoluto mes a mes. Pero si le preguntas «¿cuál es más inestable?», te da una impresión equivocada: la plata parece tranquila y el oro nervioso. El de la derecha — todo en cambio porcentual desde enero — responde bien a esa segunda pregunta, y revela lo contrario: la plata oscila bastante más (rango ~27 %) que el oro (~11 %). Ninguno de los dos miente: cada uno está construido para una pregunta distinta, y el error sería pedirle a uno la respuesta del otro.

👁️ No te fíes de tus ojos. El último ejemplo es el más radical. En la próxima figura — un heatmap de expresión génica — hay dos celdas marcadas: el Gen B en la muestra 4 y el Gen H en la muestra 6. Míralas y apuesta: ¿cuál de las dos tiene el valor más alto? Quédate con tu respuesta.
Aquí está el heatmap (Fig. 6.7):

¿Tu respuesta? Casi todo el mundo las ve distintas — una más oscura, la otra más clara. Hagamos entonces la prueba decisiva: quitemos el contexto. Pintamos de gris todas las celdas de alrededor y dejamos sólo las dos marcadas (Fig. 6.8).

La sorpresa es total: las dos celdas contienen exactamente el mismo valor. Lo que las hacía parecer distintas era el contexto cromático local que las rodea, una ilusión perceptual que el ojo no puede evitar. Aquí el contexto ya no influye sólo en la interpretación: define lo que el ojo cree ver. El color de una celda no se percibe en sí mismo — se percibe en relación con lo que tiene al lado.
La moraleja se repite: la decisión de qué mostrar (ventana, escala, unidades) es parte del diseño, no un detalle técnico. Es lo que hace que la misma tabla pueda volverse argumento a favor de cosas opuestas. Los efectos específicos del recorte del eje Y — y la trampa de mostrar sólo una parte del panorama, lo que llamamos alcance limitado — se tratan a fondo en la Cápsula 07 (Cortar el eje Y y otros errores numéricos comunes), donde el problema técnico se aborda con todos sus matices.
Puntos de vista: el contexto define la audiencia, la audiencia define la técnica
🏫 Mismos datos, dos lectores. Imagina las notas de un curso entero. El padre de un alumno quiere una sola cosa: ¿cómo le va a su hijo? El director del colegio quiere otra: ¿cómo le va al curso en cada materia? Son exactamente los mismos números — pero cada uno necesita un gráfico distinto. Veamos por qué.
Al elegir cómo presentar los datos, hay que preguntarse desde qué perspectiva es más útil hacerlo — y eso depende enteramente del contexto y de quién va a leer el gráfico.
El ejemplo escolar lo deja claro. Imaginemos los resultados de un curso (Fig. 6.9). El padre de un alumno quiere ver el rendimiento de su hijo — le interesa el alumno como entidad, no la comparación entre todos. El director de la escuela quiere ver el rendimiento del curso en su conjunto — le interesa cada materia transversalmente, no el detalle de un solo alumno.

Son dos puntos de vista radicalmente distintos sobre los mismos datos: el padre necesita una visión centrada en el objeto (un alumno = una forma compacta que se lee de un vistazo), el director una visión centrada en los atributos (cada materia = un eje que se lee a través de todos los alumnos). El contexto — la audiencia y su pregunta — define cuál técnica es la correcta.
Cada visión se materializa con una técnica gráfica distinta. Para la visión centrada en el objeto, la rosa de Nightingale (Fig. 6.10) representa a cada alumno como una forma circular compacta donde cada materia es un pétalo: lees un alumno entero de un solo vistazo. Para la visión centrada en los atributos, las coordenadas paralelas (Fig. 6.11) ponen cada materia en un eje vertical y cada alumno como una línea que cruza los ejes: lees todos los alumnos en una materia de un solo vistazo, a costa de perder la "entidad alumno". La variante coloreada por estudiante (Fig. 6.12) intenta recuperar parcialmente la visibilidad del objeto — funciona con pocos alumnos, se vuelve ilegible con 20-30.



No hay técnica "mejor": hay técnica adecuada al contexto. Más adelante volveremos a estas técnicas desde el punto de vista de la multidimensionalidad (cómo mostrar 3, 4 o más variables al mismo tiempo), donde la rosa y las coordenadas paralelas se inscriben en un repertorio más amplio de soluciones.
Graphicacy y Lie Factor: por qué Excel miente por defecto

Existe algo llamado 'Graphicacy': la capacidad de leer y crear gráficos bien hechos. Y nuestro gran villano predeterminado es Excel, que corta el eje Y solito y te aumenta el 'Factor de Mentira'.
Qué es la graphicacy
La graphicacy, como la definen Aldrich y Sheppard, es “la capacidad de comprender y presentar información en forma de bocetos, imágenes, diagramas, mapas, gráficos y otros formatos no textuales y bidimensionales”. Esta competencia es esencial tanto para la producción como para la interpretación de representaciones visuales.
En el contexto de las malas visualizaciones, la graphicacy es una herramienta fundamental para evitar errores y malentendidos. La falta de graphicacy puede manifestarse de dos maneras:
- En los receptores de visualizaciones: Una comprensión insuficiente puede llevar a interpretaciones incorrectas de los datos visualizados. Los ciudadanos, directivos y otros tomadores de decisiones que carecen de esta competencia corren el riesgo de ser engañados por representaciones visuales inadecuadas o malintencionadas.
- En los creadores de visualizaciones: La incapacidad para presentar datos de manera clara y precisa puede resultar en visualizaciones que no sólo son ineficaces, sino que pueden distorsionar la realidad. Incluso aquellos que trabajan en el ámbito de la visualización de datos deben desarrollar tanto la capacidad de comprender como de presentar información visual de forma adecuada.
Para prevenir las malas visualizaciones, es esencial que tanto los productores como los receptores de visualizaciones cultiven un alto nivel de graphicacy (Fig. 7.1). Esto les permitirá crear y evaluar representaciones visuales de datos con un enfoque crítico, asegurando que la información se transmita de manera clara, precisa y ética.

¿Engañar es difícil... o no?
🎭 Engañar con datos es facilísimo — y, casi siempre, sin querer. La intuición común dice lo contrario: que para mentir con un gráfico hace falta ser un manipulador sofisticado, con mala fe y conocimientos avanzados. Es exactamente al revés: harta visualización engañosa la produce gente honesta que simplemente apretó un botón.
Tan es así que investigadoras como Rogowitz y colegas prefieren reformular la pregunta: en lugar de estudiar "cómo se engaña", enseñan cómo no engañar sin querer.
¿Por qué es tan fácil? Porque las herramientas de oficina (Excel a la cabeza, pero no la única) toman decisiones por defecto que distorsionan los datos sin pedir permiso: cortan el eje Y, eligen colores arbitrarios, escalan por radio en lugar de por área. Si la graphicacy del receptor fuera alta, esos errores se detectarían en segundos; pero como la mayoría del público no fue entrenado para leer gráficos críticamente, las distorsiones pasan invertidas como verdad. El problema, entonces, no es sólo de quien produce — es también de quien consume.
Hay un recurso útil que cataloga estos errores comunes: la sección "Caveats" de From Data to Viz. Estudiarla periódicamente entrena el ojo para detectar la mentira accidental antes de que termine pegada en un informe.
Factor de mentira (Lie Factor)
En el campo de la visualización de datos, es común encontrarse con gráficos que, intencionadamente o no, distorsionan la realidad de los datos que pretenden representar. Estas malas visualizaciones pueden engañar a los espectadores, exagerando, minimizando o incluso ocultando aspectos cruciales de la información presentada. Una herramienta útil para analizar y comprender estas distorsiones es el concepto del Lie Factor, introducido por Edward Tufte.
El Lie Factor es un concepto introducido como una medida para evaluar la veracidad de una visualización de datos. Este factor compara la magnitud del cambio representado en un gráfico con la magnitud del cambio real en los datos, permitiendo medir el grado de distorsión en la información.
El Lie Factor se calcula con la siguiente fórmula:
Lie Factor = Cambio en la representación visual / Cambio en los datos
- Cambio en la representación visual: Se refiere a la diferencia en tamaño, longitud o área en el gráfico.
- Cambio en los datos: Se refiere a la diferencia real en los valores de los datos.
Interpretación del Lie Factor:
- Lie Factor ≈ 1: La visualización es precisa y representa fielmente los datos.
- Lie Factor > 1: La visualización exagera el cambio en los datos, haciendo que las diferencias parezcan mayores de lo que realmente son.
- Lie Factor < 1: La visualización minimiza el cambio en los datos, haciendo que las diferencias parezcan menores de lo que realmente son.
¡Microsoft Excel es una herramienta excelente para crear visualizaciones engañosas!
🔍 Pongámosle número a una mentira. En la próxima figura verás, a la izquierda, el gráfico que Excel genera automáticamente con ciertos datos; a la derecha, el mismo dato con el eje Y empezando en cero. Antes de leer la respuesta, mira el de la izquierda y estima: ¿cuántas veces más grande parece la diferencia, comparada con la diferencia real?
La comparación (Fig. 7.2) lo deja claro.

En el gráfico de la izquierda, generado automáticamente por Excel, la diferencia visual entre los valores es aproximadamente 3,5 veces más grande que la diferencia real. El Lie Factor es, por lo tanto, 3,5 — Excel exageró la realidad tres veces y media, y nadie se lo pidió.
Cortar el eje Y y otros errores numéricos comunes

La controversia: ¿Cortar el eje Y o no? En barras, pecado. En líneas, a veces es válido. Y cuidado con los acumulados, los ejes mal proporcionados y los porcentajes que no suman 100.
¿Cortar o no cortar el eje Y?
Cortar o no cortar el eje Y es uno de los temas más debatidos en la visualización de datos. La controversia gira en torno a si el eje Y debe comenzar siempre en cero o no; una ilustración satírica al estilo de Huff (Fig. 8.1) ironiza sobre el problema de la distorsión que aparece al cortarlo. Analicemos por qué es difícil alcanzar un consenso en este tema.

Comenzar el eje Y en un valor distinto de cero puede ser engañoso, especialmente en gráficos de barras, donde las diferencias en la longitud de las barras se interpretan como proporcionales a los valores representados. Si el eje Y no comienza en cero, las diferencias entre las barras pueden parecer mucho mayores de lo que realmente son. Un ejemplo extremo de esta distorsión (Fig. 8.2) muestra dos barras de valores casi idénticos donde una se ve mucho más alta que la otra porque el corte del eje amplifica la diferencia.

Edward Tufte, un reconocido experto en visualización de datos, sugiere que en general, en una serie temporal, se debe utilizar una línea base que muestre los datos relevantes en lugar de insistir en que el eje Y comience en cero. En estos casos, el objetivo es enfatizar el cambio en la variable dependiente (generalmente el valor Y) a medida que cambia la variable independiente (generalmente el valor X), no necesariamente su relación con el cero.
En un gráfico de líneas, especialmente en series temporales, no siempre es necesario que el eje Y comience en cero. La intención principal es destacar las tendencias y fluctuaciones en los datos, por lo que cortar el eje Y puede ser aceptable y a veces incluso necesario para hacer visibles las variaciones significativas.
Cuando es necesario cortarlo, conviene señalarlo al lector con alguna convención visual: el catálogo (Fig. 8.3) reúne las más habituales (zig-zag en la base, línea quebrada, hueco visible en el eje, etc.).

La decisión de cortar o no el eje Y depende en gran medida del tipo de gráfico y del mensaje que se desea transmitir:
- Gráfico de barras: Existe un consenso general de que en este tipo de gráfico, el eje Y debe comenzar en cero. Esto es porque las barras se utilizan para representar magnitudes absolutas, y cualquier alteración en la base puede distorsionar la percepción visual de esas magnitudes. Si es indispensable cortarlo, hay que señalarlo con alguna de las convenciones vistas arriba.
- Gráfico de líneas: Aquí, sin embargo, no hay consenso. En general, no es necesario que el eje Y comience en cero, ya que el objetivo es mostrar las tendencias y cambios en los datos a lo largo del tiempo o entre categorías.
⚖️ El mismo corte, dos veredictos opuestos. Aquí viene lo difícil. Cortar el eje Y no es ni pecado ni virtud en abstracto: en los próximos dos gráficos de líneas verás que la misma operación — recortar el eje — engaña en un caso y es la lectura honesta en el otro. La pregunta de fondo: ¿qué los distingue?
Aun así, también en gráficos de líneas el corte del eje puede exagerar la magnitud real de las fluctuaciones; lo importante es contextualizar cada decisión. El PIB de EE. UU. cayendo de 6,6 % a 5,5 % (Fig. 8.4) aparece como un colapso casi vertical cuando el eje arranca en 5,25 % — pero la misma curva sobre un eje desde cero es apenas una pendiente suave: aquí el recorte engaña. En cambio, el calentamiento global (Fig. 8.5) se vuelve invisible si el eje Y va de 0 °F al promedio actual, pero acotándolo a 56-59 °F la tendencia ascendente aparece claramente — y en ese contexto la lectura honesta es la del eje recortado, porque "unos pocos grados de cambio pueden tener consecuencias catastróficas". El criterio no es una regla rígida: es entender qué mensaje merece visibilidad.


Alcance limitado: cuando recortas sin avisar
El eje Y cortado es un caso particular de un problema más general: el alcance limitado. Cuando un gráfico muestra sólo una parte del panorama —sea por recortar el período, por excluir categorías, por elegir un subconjunto de países— corre el riesgo de inducir conclusiones que la imagen completa desmentiría.
Ya lo vimos en la Cápsula 05 con el caso paradigmático del recorte temporal: el interés por los vinilos cambia de "está volviendo" a "está muerto" según la ventana temporal elegida (Fig. 8.6). Mismo dato, dos relatos comerciales opuestos — y la diferencia es sólo el recorte.
El recorte no es necesariamente engañoso: a veces es justificable y necesario — no puedes graficar todo siempre. Pero cuando se hace sin avisar al lector, deja de ser una decisión de diseño y pasa a ser una omisión interesada.
📐 La regla es de una sola línea: si recortas, dilo. Recortar el período, excluir categorías, mostrar sólo un subconjunto de países — todo eso es legítimo. Lo que no es legítimo es hacerlo en silencio. Una señal clara — una nota, un quiebre dibujado en el eje, un subtítulo honesto — convierte una omisión sospechosa en una decisión de diseño transparente.
La Importancia de Respetar los Estándares en la Visualización de Datos
Más allá del eje Y cortado, hay otras decisiones de diseño que rompen las convenciones que el lector da por descontadas — y, al hacerlo, lo engañan sin que se dé cuenta.
Un primer ejemplo clásico: invertir el eje Y. Estamos acostumbrados a que un eje vertical crezca de abajo hacia arriba; cuando una visualización de Business Insider mostró las muertes por armas de fuego en Florida con el eje invertido (Fig. 8.7), la lectura natural sugería que los homicidios bajaron entre fines de los 90 y 2010, cuando en realidad pasó exactamente lo contrario. El gráfico no mentía en los números — mentía en la convención.

Otro caso recurrente es el uso engañoso del color para etiquetar proporciones. Un correo de Google describía el comportamiento del 41% de los clientes, pero el gráfico de dona pintaba en verde el 59% del círculo (Fig. 8.8). El ojo lee el color saturado como "lo importante", el lector asume que el verde es ese 41%, y se queda con la lectura opuesta a la real.

La regla es simple: una visualización debe enseñar algo nuevo, y para hacerlo necesita respetar las convenciones visuales del lector. Romper esas convenciones puede ser una decisión legítima — pero exige una razón fuerte y, sobre todo, una señal clara que advierta al lector.
Escalado incorrecto: ejes mal proporcionados
Otra trampa frecuente es el eje numérico mal proporcionado (Fig. 8.9): aunque el eje empiece en cero, las distancias visuales entre valores no son lineales. Si entre 10.000 y 20.000 hay tanta separación como entre 20.000 y 30.000 — pero entre 30.000 y 40.000 hay el triple — el lector lee la longitud de las barras como si reflejara la magnitud, pero esa lectura es falsa.

A veces el problema es aún más burdo: dos barras con valores casi iguales se dibujan con alturas claramente distintas, sencillamente porque alguien tipeó los datos a mano en el editor gráfico sin que el software validara la proporción.
La lección es directa: cuando una visualización codifica magnitudes con longitud o posición, hay que verificar que la escala sea uniforme. Es un control trivial — un eje, una regla, un ratio — pero su ausencia distorsiona todo el gráfico.
Diferencias acumuladas vs diferencias reales
Las gráficas acumuladas tienden a sugerir crecimiento incluso cuando los datos reales bajan (Fig. 8.10). Si cada barra suma a la anterior, la silueta siempre sube (mientras los valores sean positivos), y el ojo lee esa silueta como "tendencia". Pero la tendencia real podría ser la inversa: una caída sostenida en los valores incrementales.

Por eso, cuando se quiere comunicar evolución, conviene mostrar las diferencias reales —los valores periodo a periodo— y reservar las acumuladas para responder otra pregunta distinta ("¿cuánto llevamos en total?"). Y si por algún motivo se prefiere la versión acumulada, hay que contextualizarla con claridad: explicar que es una suma corrida y no la magnitud del periodo.
Inconsistencias numéricas
Suena absurdo, pero ocurre con frecuencia: gráficos de pastel cuyos porcentajes no suman 100%, leyendas que no coinciden con los colores reales del gráfico, totales que cambian entre el título y el cuerpo. Este tipo de error no es estilístico — es un error de control de calidad que destruye la credibilidad de toda la visualización.
Cuando un pie chart con tres porciones suma 96% (o 105%), el lector deja de confiar y, con razón, sospecha que el resto del gráfico también está mal. Verificar que los números cierran es una de las revisiones más baratas y más importantes antes de publicar.
🥧 Suma las porciones. El próximo es un caso real, llevado al extremo: una encuesta a navegantes sobre los equipos más útiles a bordo, presentada como gráfico de pastel. Antes de leer la explicación, míralo y suma mentalmente sus porciones. ¿Te da 100 %?
Aquí está el pastel (Fig. 8.11):

Si intentaste sumar, te habrás rendido pronto: las porciones suman ¡192 %! El responsable original eligió mal el tipo de gráfico — un pastel implica «fracciones de un mismo todo», pero las respuestas eran de selección múltiple. El resultado es un gráfico que se ve profesional (con sombreado 3-D incluido) y que viola la regla más básica de su género en el primer vistazo.
El uso del color como ruido vs como información — incluyendo el ejemplo de las exportaciones de armas — se desarrolla en la Cápsula 10 (El color en InfoVis), donde se trata como parte del tratamiento sistemático del color.
Ejes duales, bins traicioneros y correlaciones espurias

Hay trampas sutiles: omitir datos, jugar con los bins, e inventar correlaciones. ¿Crees que vender helados atrae tiburones? Correlación NO es causalidad.
Los Gráficos con Ejes Duales y sus Alternativas
Los gráficos con dos ejes diferentes (usualmente “Y”) - también conocidos como gráficos de doble eje, gráficos de eje dual o gráficos superpuestos - son una herramienta comúnmente utilizada para mostrar dos series de datos con diferentes magnitudes o medidas en un solo gráfico. Sin embargo, su uso puede ser problemático, ya que pueden confundir a los lectores y llevar a interpretaciones incorrectas.
El principal problema con estos gráficos radica en que las escalas de los ejes Y son arbitrarias y pueden inducir a error sobre la relación entre las dos series de datos. Por ejemplo, este gráfico (Fig. 9.1) muestra el PIB global y el PIB de Alemania con dos ejes Y independientes: las pendientes parecen comparables aunque las magnitudes son muy diferentes, una fuente típica de confusión.

Los gráficos de doble eje son difíciles de leer para la mayoría de las personas, ya que requieren un esfuerzo adicional para entender la relación entre las dos series de datos. Investigaciones han demostrado que estos gráficos tienden a generar confusión y disminuyen la precisión en la interpretación de los datos.
Hay alternativas para mostrar este tipo de gráfico:
-
Gráficos Lado a Lado (Fig. 9.2): separar las dos series de datos en gráficos independientes, cada uno con su propio eje Y en escala natural, permite mantener la integridad de las escalas y facilita la comparación visual sin la ilusión de paralelismo.

Fig. 9.2: Los mismos datos del PIB pero separados en dos gráficos independientes, cada uno con su escala natural. Primera alternativa honesta al doble eje: cada serie respira en su propia magnitud, sin sugerir paralelismos engañosos. -
Gráficos Indexados (Fig. 9.3): normalizar ambas series a un mismo punto de partida (por ejemplo, valor inicial = 100) y mostrar el cambio relativo en lugar de los valores absolutos. Es ideal para comparar tasas de crecimiento entre magnitudes heterogéneas.

Fig. 9.3: Líneas indexadas a un mismo punto de partida (valor inicial = 100). Segunda alternativa honesta al doble eje: cuando lo que importa es comparar tasas de crecimiento entre magnitudes heterogéneas, este gráfico lo hace sin trampa, en un solo eje, dejando claro que se está comparando el cambio porcentual.
Un caso similar se discutió en una cápsula anterior, donde se analizó cómo la decisión de usar dos ejes depende de la pregunta que se desea destacar en el gráfico.
Cuando se utilizan dos ejes en un mismo gráfico, también existe el riesgo de sugerir una causalidad indebida entre dos series de datos. Esto ocurre porque los dos ejes pueden dar la impresión de que hay una relación causal entre las variables, cuando en realidad podría tratarse solo de una correlación.
Este caso (Fig. 9.4) ilustra el riesgo: un doble eje hace parecer una correlación negativa fuerte, pero en realidad el eje derecho varía muy poco (entre 10 y 10,7) mientras que el izquierdo cubre un rango mucho más amplio (de 0 a 10), de modo que la relación visual es un artefacto de las escalas.

Correlación no implica causalidad: Este principio fundamental en estadística indica que, aunque dos variables muestran una correlación, no significa necesariamente que una variable cause la otra. El uso de dos ejes puede amplificar esta ilusión de causalidad.
🦈 ¿El helado atrae tiburones? Mira el próximo gráfico: las ventas de helado y los ataques de tiburones siguen exactamente la misma curva mes a mes, con pico en julio-agosto. La correlación es altísima — real, medible. Entonces, ¿comer helado provoca ataques de tiburones? Antes de reírte, fíjate bien: el dato no miente. Lo que falla es la inferencia que uno hace con él.
El gráfico (Fig. 9.5) es el primero de dos clásicos de las correlaciones espurias, y es estacional. La correlación entre helados y tiburones es altísima — y completamente espuria. No es que comer helado provoque ataques de tiburones (ni viceversa): durante el verano más gente va a la playa Y más gente compra helados. La causa común — el calor estival — explica las dos series a la vez. En el lenguaje de la estadística, el verano es una variable de confusión.

El segundo ejemplo (Fig. 9.6) es geográfico y mucho más absurdo: si trazamos para cada país el consumo per cápita de chocolate (en kg/año) frente al número de premios Nobel por cada 10 millones de habitantes, sale un scatter con r = 0,79 — una correlación fortísima. Suiza arriba a la derecha (mucho chocolate, muchos Nobel), China abajo a la izquierda. La inferencia ingenua — "comer chocolate te hace ganar el Nobel" — es absurda; pero la correlación es real. Aquí también hay variables de confusión: la riqueza nacional, los sistemas educativos, incluso el clima frío del norte de Europa, podrían explicar a la vez ambas series sin que una cause la otra.

Por qué es problemático:
- Distorsión de la percepción: Los usuarios del gráfico pueden interpretar erróneamente la relación entre las dos variables como causal, cuando en realidad podría ser solo una coincidencia o estar influenciada por otra variable no considerada. Un ejemplo notable es la coincidencia entre el declive del uso de Internet Explorer y el declive del número de asesinatos en EE. UU. (Fig. 9.7), que recopiló Tyler Vigen.
- Manipulación de los datos: El uso de dos ejes puede ser utilizado para enfatizar un efecto que no es real, llevando a conclusiones engañosas.

Evitar el problema: Es importante ser claros en el contexto y en la narrativa de los datos. Si se utilizan dos ejes, es esencial explicar claramente el motivo del uso y asegurarse de que no se esté sugiriendo erróneamente una causalidad sin pruebas concretas.
La Importancia de la Elección del Tamaño de Bin en un Histograma o Escala de Colores
El histograma es un tipo de gráfico que toma como entrada una variable numérica y la divide en varios intervalos, llamados bins. La altura de cada barra en el histograma representa el número de observaciones dentro de cada bin. Aunque es un gráfico muy común, la elección del tamaño del bin puede tener un impacto significativo en la interpretación de los datos.
Un histograma divide los valores de una variable numérica en rangos específicos (bins) y cuenta cuántos valores caen dentro de cada rango. La elección del tamaño del bin (es decir, la amplitud de cada rango) determina cuántos datos se agrupan en cada barra, lo que afecta directamente la percepción de la distribución de los datos.
📊 Los mismos precios, dos tamaños de bin. Vamos a mirar la distribución de los precios por noche de los departamentos de Airbnb en la Riviera Francesa — varían entre 10 y 300 euros, con la mayoría entre 60 y 150. Primero los agruparemos en intervalos (bins) de 10 euros; después, en bins de 2. Es exactamente el mismo dato — fíjate cómo el ancho del bin decide qué patrón ves, y cuál se esconde.
Con bins de 10 euros (Fig. 9.8) se ve una curva relativamente suave: la moda cae alrededor de los 80-100 euros y la distribución parece tranquila, sin sorpresas.

Ahora reducimos el bin a 2 euros (Fig. 9.9). El cambio revela algo que el bin grueso ocultaba por completo: aparecen picos pronunciados en valores muy específicos — 58, 64, 69, 75, 80 euros… — porque los anfitriones prefieren ciertos precios psicológicamente atractivos.

La elección del tamaño del bin puede alterar dramáticamente la interpretación de los datos. En el primer histograma, con bins de 10 euros, se obtiene una visión general de la distribución de los precios. Sin embargo, al reducir el tamaño del bin a 2 euros, se descubre un patrón más detallado que muestra la preferencia por ciertos precios específicos. Este detalle adicional puede ser crucial para un análisis más profundo. Un bin demasiado grande puede ocultar patrones importantes, mientras que un bin demasiado pequeño puede introducir ruido en los datos. La clave está en encontrar un equilibrio que permita representar los datos de manera clara y precisa, según el objetivo del análisis.
De forma similar, también en la elección de los intervalos de color hay que tener cuidado. Cambiando los cortes, dos mapas coropléticos del mismo dataset pueden verse muy diferentes, como muestra el ejemplo (Fig. 9.10): ambos mapas muestran el ingreso medio familiar por condado de EE. UU. (USD, estimado), con la misma paleta verde y las mismas etiquetas de leyenda (Bajo / Medio / Alto). A la izquierda los cortes se eligen por tertiles y se ve claramente que no hay equidad: el Sur aparece más pobre y el Noreste y las costas más ricas. A la derecha el bin central abarca un intervalo absurdamente amplio (USD 10k – USD 250k) que mete TODOS los condados en un solo tono: el país entero parece perfectamente equitativo, aunque los datos no han cambiado. Mismo dataset, misma paleta, mismas etiquetas — sólo cambian los rangos numéricos, y con ellos la desigualdad aparece o se esconde por completo.

Omitir Datos en las Gráficas
Las gráficas creadas con datos omitidos eliminan información crucial que puede afectar la interpretación y las conclusiones derivadas.
✂️ ¿Crecimiento o ilusión? El próximo scatter muestra una serie de crecimiento — pero sólo con los años pares en el eje X. Míralo: se ve limpio, lineal, casi monótono. ¿Te lo creerías? Guarda tu impresión, porque enseguida vamos a agregar los años que faltan.
En esa versión con datos faltantes (Fig. 9.11) el crecimiento parece más lineal y monótono de lo que realmente es, simplemente porque se han omitido de forma sistemática los datos intermedios. Esto puede llevar a conclusiones erróneas: se pierde el contexto completo que los datos originales proporcionan.

Por otro lado, el mismo diagrama con todos los años en el eje X (Fig. 9.12), pares e impares, revela la verdadera distribución y variabilidad: la serie tiene hartas más fluctuaciones que las que mostraba la versión recortada, lo que permite una interpretación más precisa y fundamentada.

Área vs radio, 3D y gráficos de pastel: tres trampas frecuentes

¡Silencio! Hoy destruimos otra trampa: si quieres que un círculo represente un número, no escales el radio, ¡escala el área! De lo contrario, exagerarás la diferencia al cuadrado.
Escalado Incorrecto: Usando el Radio/Lado en Lugar del Área
Una práctica común en la visualización de datos consiste en escalar un componente gráfico a un valor numérico. Por ejemplo, en un gráfico de barras, las longitudes de las barras se escalan según los valores. Sin embargo, cuando el valor se escala en función del área, y no solo de una dimensión, esto puede producir un efecto cuadrático para un cambio lineal, amplificando las diferencias de manera significativa.
⭕ El círculo de Obama. En 2011, en el discurso del Estado de la Unión, Barack Obama mostró el PIB de cinco países como círculos. El de Estados Unidos se veía gigantesco, aplastante. La pregunta: ¿la economía de EE. UU. es de verdad tan descomunalmente mayor? El truco está en una decisión que parece inocente — escalar el radio del círculo en vez de su área.
Un ejemplo de este error se observa justamente en ese discurso, donde el PIB de cinco países se mostró con círculos cuyo radio escalaba según el tamaño de cada economía. La comparación entre versiones (Fig. 10.1) muestra el problema en tres pasos: en el gráfico original (a la izquierda), la economía de Estados Unidos parece desproporcionadamente mayor que las otras, porque el radio escala linealmente pero el área escala cuadráticamente; al superponer copias del círculo de Francia (en el centro) se ve cuántas Francias caben según radio vs según área; y en la versión corregida del blog Fast Fedora (a la derecha), con escalado por área, Estados Unidos sigue siendo el más grande pero la diferencia ya no parece grotesca.

Es importante recordar que, al trabajar con objetos en 2D, la escala debe basarse en el área y no en el radio/lado.
El esquema con tres cuadrados (Fig. 10.2) hace explícito el efecto: en términos de área, el cuadrado mediano es realmente 4 veces más grande que el pequeño, y el grande es 9 veces más grande, porque duplicar el lado cuadruplica el área. El mismo concepto se aplica a los círculos.

Uso de Áreas para Representar Valores Numéricos
El radio mal escalado es un error de mecánica; pero hay un problema más de fondo: el área, en sí misma, es una metáfora pobre para representar valores. El ojo humano no es eficiente al interpretar áreas como cantidades. Comparar el tamaño relativo de varias burbujas exige tiempo y es propenso a errores: el lector estima por inspección, no calcula. Si los mismos valores se representan con barras alineadas en una base común, la lectura es inmediata y precisa. La regla práctica es dura: si puedes evitar codificar una magnitud con área, evítala.
🫧 El área no está prohibida — está reservada. Tiene sentido sólo cuando ya agotaste las codificaciones más precisas (posición, longitud, barras) y aun así te falta lugar para una variable más. Ese es el caso del gráfico de burbujas: empaqueta tres variables numéricas en cada punto — eje X, eje Y y tamaño — y a veces una cuarta, categórica, con el color. Cuando de verdad necesitas esa densidad, el área se gana su lugar.
El gráfico de burbujas (Fig. 10.3) muestra ese uso legítimo. Aun así, antes de recurrir a él conviene preguntarse: ¿realmente necesito esa tercera variable en el mismo gráfico, o un par de barras contaría la historia mejor? El área es la última herramienta del cajón, no la primera.

Uso de Gráficos 3D sin Justificación
El uso de objetos tridimensionales en visualizaciones de datos es popular, pero casi siempre afecta negativamente la precisión y la velocidad con la que se interpreta un gráfico. El motivo es uno solo: la perspectiva agranda lo que está al frente y encoge lo que está al fondo, así que los valores dejan de leerse y empiezan a adivinarse.
🥧 ¿Cuál sector es más grande? En el próximo gráfico de pastel 3D hay dos sectores en juego: uno abajo, «South», y otro arriba, «North». Míralo y decide cuál te parece más grande — antes de leer cuál lo es de verdad.
Aquí está el pastel 3D (Fig. 10.4):

Si te pareció que el sector de abajo es el mayor, caíste en la trampa: ése es el 30 %, y el de arriba — que se ve más chico — es en realidad el 35 %. La cámara, ubicada por debajo, infla la porción frontal hasta que un 30 % se ve igual de grande — o más — que un 35 %. No es una simulación ajustada a mano: es pura geometría 3D proyectada en perspectiva, y por eso los pasteles 3D mienten siempre. Y cuando además son "exploded", con los sectores separados, el problema todavía empeora.
El mismo defecto aparece en el gráfico de barras 3D, frecuentemente visto en Excel. Un ejemplo típico (Fig. 10.5) lo deja claro: las barras del fondo se ven más chicas que las del frente aunque tengan el mismo valor, unas tapan parcialmente a otras, y encontrar un valor concreto se vuelve un ejercicio de adivinación.

La recomendación es directa: evita los gráficos 3D y opta por alternativas planas — barras planas y, a ser posible, ningún pastel.
Gráficos de Pastel: Una Elección Problemática
📊 Intenta ordenar los pasteles. El próximo gráfico reúne varios pasteles con proporciones distintas. Trata de ordenarlos del sector más grande al más chico. Vas a notar lo incómodo que es: comparar ángulos es una tarea que el ojo humano hace mal y despacio. Enseguida verás los mismos datos como barras — y la diferencia es brutal.
El gráfico de pastel divide un círculo en sectores que representan proporciones de un total. La comparación de varios pasteles con proporciones distintas (Fig. 10.6) deja clara su debilidad: para ordenarlos hay que estimar ángulos relativos, una tarea perceptiva difícil y propensa a errores.

Un gráfico de barras, por el contrario, facilita la comparación precisa y revela patrones ocultos que pueden ser cruciales para la narrativa de los datos: los mismos valores representados como barras alineadas en una base común (Fig. 10.7) se comparan de manera inmediata, sin ambigüedad.

Uno de los pocos casos en los que un gráfico de pastel funciona bien es cuando se comparan apenas dos valores — por ejemplo, "¿te gustó la película? sí / no" (Fig. 10.8). Con solo dos sectores, el ojo distingue sin esfuerzo cuál es mayor.

En la mayoría de los otros casos, es mejor utilizar un gráfico de barras.
El color en InfoVis: tres dimensiones, accesibilidad, ruido y coherencia

El color es la herramienta visual más poderosa — y la más mal usada. Tiene tres dimensiones, no una. Casi el 8 % de los hombres no distingue rojo de verde. Y si "Producto A" cambia de color entre gráficos, el lector se pierde.
El color es probablemente la señal visual que más se equivoca al usar. La razón es que parece simple — "elijo un color" — pero en realidad es una herramienta de tres dimensiones independientes, con problemas de accesibilidad serios, con riesgo de convertirse en puro ruido visual si se usa mal, y con un requisito implícito de coherencia entre gráficos del mismo informe. Esta cápsula recorre los cuatro frentes en orden.
Las tres dimensiones del color: tono, saturación y brillo
🎨 Un color son tres decisiones. Piensa en el azul de una barra: parece una sola elección — "puse azul". Pero todo color tiene un tono, una saturación y un brillo, y las tres dimensiones son independientes entre sí. La próxima figura descompone el color en esos tres ejes.
La descomposición (Fig. 11.1) deja claro lo que está en juego: cada uno de los tres ejes se puede mover por separado para codificar una variable distinta — categoría, magnitud, énfasis. Quien lo entiende deja de usar el color como decoración y empieza a tratarlo como una variable visual con tres canales de información.

- Tono (hue) — lo que normalmente llamamos "color" en lenguaje cotidiano: rojo, azul, verde, amarillo. Es la dimensión más útil para codificar categorías distintas (mutuamente excluyentes, sin orden).
- Saturación — qué tan puro o intenso es ese tono, en una escala que va del gris al color totalmente saturado del mismo brillo. Útil para codificar magnitud ordinal dentro de un mismo tono.
- Brillo (o luminosidad) — qué tan claro u oscuro es el color, independientemente del tono. Es la dimensión que el ojo lee con más precisión cuantitativa, y la única que sigue funcionando bien para personas con daltonismo.
La regla práctica: usa tono para categorías, saturación o brillo para magnitudes. Mezclar las dos cosas (tono que codifica orden, por ejemplo arcoíris para una variable continua) es un error clásico — el ojo no lee orden en el espectro de tonos.
Daltonismo y paletas accesibles
Es recomendable evitar el uso de escalas de colores como verde, naranja y rojo en la visualización de datos, especialmente cuando se espera que el gráfico sea accesible para personas con daltonismo. La comparación (Fig. 11.2) muestra cómo se percibe una escala verde-naranja-rojo en visión normal frente a la protanopía (deficiencia en la percepción del rojo) y la deuteranopía (deficiencia en la percepción del verde): en las versiones daltónicas, varios tonos colapsan y se vuelven prácticamente indistinguibles.

Estas combinaciones de colores suelen ser problemáticas porque las personas con daltonismo tienen dificultades para distinguir entre estos colores debido a la falta de contraste y a la confusión entre tonalidades similares. En lugar de esto, es preferible utilizar una paleta como la que se muestra a continuación (Fig. 11.3), con tonos azul, amarillo y naranja bien diferenciados en luminosidad, que se mantiene legible tanto en visión normal como en protanopía y deuteranopía.

🗺️ El mapa que se traiciona a sí mismo. Lo que viene es un mapa mundial de la prevalencia del daltonismo, pintado con una escala verde-amarillo-rojo. Léelo un momento: ¿dónde vive la mayor proporción de población daltónica? Enseguida verás ese mismo mapa tal como lo percibe una persona daltónica — y vas a entender la ironía.
El daltonismo es más común de lo que se piensa. El mapa de prevalencia mundial (Fig. 11.4) lo muestra con claridad — bandas del 7-9 % de población masculina daltónica en gran parte de Europa y Norteamérica, alrededor del 3-5 % en Sudamérica y Asia, y menos del 1 % en zonas de África subsahariana. Cerca del 8 % de los hombres de ascendencia europea es daltónico: en cualquier audiencia internacional, la cantidad de personas afectadas es enorme.

Y ahora el mismo mapa, simulado tal como lo ve una persona con deuteranopía (Fig. 11.5): la escala rojo-verde colapsa en un mar de tonos olive indistinguibles. Ahí está la ironía — un mapa que habla justamente del daltonismo, dibujado de modo que quien lo tiene no puede leerlo. Lo que para ti es información, para esa persona es ruido. La moraleja es clara: si no quieres este efecto, no uses rojo y verde.

El color como ruido vs información
Los colores son una herramienta poderosa cuando se usan deliberadamente para distinguir grupos o variaciones; pero un uso indiscriminado los convierte en ruido visual que distrae del mensaje real del gráfico.
🌈 Veinte barras, veinte colores. El próximo gráfico muestra los veinte mayores exportadores de armas de 2017, cada país pintado de un color distinto. Míralo y hazte una sola pregunta: ¿qué te dice el color de cada barra? Si la respuesta honesta es "nada", acabas de descubrir el problema.
En esa versión original (Fig. 11.6) el color es puro adorno: la audiencia gasta atención tratando de descifrar qué significa cada tono, cuando la única señal que de verdad importa es la longitud de la barra.

En cambio, con todas las barras del mismo color (Fig. 11.7) el ojo va directo a esa longitud — la cantidad de armas exportadas — sin distracciones. El gráfico dice lo mismo, pero más rápido y más claro.

La regla: usa el color sólo cuando codifica información. Si todas las barras significan lo mismo (cada barra = un país), el color no agrega nada — agrega ruido. Reserva el color para cuando el color significa algo: una categoría, una magnitud, un énfasis. Cuando el color se usa como atributo preatentivo para guiar la atención del lector a un punto específico de la historia, se trata en detalle en la Cápsula 18 (Borralo, sección "Resaltar un punto").
Mantén la consistencia cromática entre gráficos
🧩 Síguele el rastro al Producto A. El próximo par de gráficos describe un mismo informe sobre cinco productos: uno de barras, otro de líneas. Busca "Producto A" en el de barras, fíjate de qué color es, y ahora encuéntralo en el de líneas. ¿Te bastó el color, o tuviste que volver a la leyenda?
Esa fricción tiene una causa. En un informe con varios gráficos relacionados es esencial usar la misma paleta: cada producto, su color, en todas las visualizaciones. Esto es harto importante. La versión rota (Fig. 11.8) hace exactamente lo contrario: "Producto A" es púrpura en el gráfico de barras y rojo en el de líneas, "Producto E" pasa de amarillo a rosa, y la conexión visual entre los dos gráficos se rompe — hay que reaprender la leyenda cada vez.

La versión correcta (Fig. 11.9) aplica la misma paleta viridis en ambos gráficos: el púrpura es siempre "Producto A", el amarillo es siempre "Producto E", y los dos gráficos se leen como un único sistema coherente. La regla es trivial pero muchas veces se rompe por descuido (cada gráfico fue construido por separado, cada uno aplicó el color por defecto del software). El costo de no respetarla es alto: la fuerza de un informe está en que sus gráficos se lean juntos, y la consistencia cromática es el pegamento que hace posible esa lectura conjunta.

Diseño iterativo: implementar, evaluar y mejorar visualizaciones

¡Atención futuros ingenieros! ¿Creían que diseñar era hacer un gráfico y mandarlo? Error. Es un ciclo: Diseña, Implementa, Evalúa, Mejora. Y nunca se enamoren de la primera versión.
El esquema básico es simple (Fig. 12.1): cuatro fases que se persiguen sin fin. Cada vuelta refina la visualización, y ninguna versión está "terminada" — sólo "lista para la próxima vuelta".

🗺 El mapa del curso. Esta cápsula es el esqueleto sobre el que se monta todo lo que sigue. Las próximas cápsulas — tipos de datos, escalas, señales visuales, evaluación con usuarios — no son temas sueltos: son las herramientas concretas que vas a encajar en este ciclo. Acá tienes el cuadro general; el detalle de cada pieza viene después.
Las preguntas adecuadas para empezar
Antes de abrir el editor, conviene plantar tres preguntas que ordenan todo lo que viene después:
- ¿Qué historia quiero contar? — Identificar un punto claro y significativo que sirva de núcleo. Sin este foco, la visualización se vuelve un catálogo de gráficos sueltos sin mensaje.
- ¿Cómo puedo contarla? — Aquí entra la creatividad: qué tipo de gráfico, qué escala, qué señales visuales. La misma información puede pasar de aburrida a memorable según cómo se presente.
- ¿Está bien lo que estoy haciendo? — La pregunta crítica: probar con usuarios, pedir feedback, verificar que el público realmente entiende lo que tú quisiste contar.
Estas tres preguntas no son un check-list lineal: son un ciclo (Fig. 12.2). Cada respuesta puede obligar a revisar la anterior. Y el ciclo se repite hasta que "todo tiene sentido", es decir, hasta que cada elemento del gráfico está alineado con el mensaje. Recién entonces vale la pena pasar a la implementación final.

Diseño e implementación
El diseño y la implementación de una visualización no deben considerarse actividades separadas y secuenciales, sino que deben entrelazarse en un proceso iterativo. Este ciclo de prueba y error permite refinar continuamente el artefacto hasta que sea lo suficientemente bueno para ser presentado al usuario. Un buen diseño surge de cuestionar el entorno actual y plantear preguntas desde la perspectiva del usuario. No se trata solo de resolver problemas existentes, sino de abrir espacio para nuevas preguntas y perspectivas.
La implementación es lo que materializa las ideas conceptuales en algo visible y comprensible: una combinación de actividades muy diversas que, juntas, transforman una idea en una visualización tangible.
✏️ Del lápiz al código. Implementar no es abrir D3 de entrada. El recorrido va de menos a más compromiso: primero bocetos rápidos en papel o pizarra, después software vectorial para afinar, y sólo al final código — D3, Plotly — cuando el diseño ya está validado. Cuanto más barato es el boceto, más fácil es descartarlo y probar otro.
En la práctica, todo suele empezar con bocetos preparatorios (Fig. 12.3) en una pizarra: las ideas iniciales se delinean de forma simple y permiten explorar enfoques visuales distintos antes de comprometerse con un diseño digital. A partir de ahí se pasa al software gráfico vectorial, que ofrece un control detallado sobre cada elemento.
Para visualizaciones más complejas, especialmente aquellas que requieren interactividad, es común el desarrollo de scripts personalizados. Utilizando librerías como D3 o Plotly (Fig. 12.4), los diseñadores pueden crear visualizaciones personalizadas que responden a necesidades específicas. Estas herramientas permiten no solo generar gráficos estándar, sino también manipular directamente cómo se presentan los datos para resaltar patrones o tendencias relevantes.
🔊 El ciclo no es sólo para gráficos. Un dato no tiene por qué quedarse quieto en una imagen: puede sonar y puede moverse. Más adelante en el curso vas a usar herramientas para lograrlo — Tone.js, que convierte datos en sonido en el navegador, y LEGO Technic, que los vuelve mecanismos que se mueven. Cambia el material, no el método: diseñar-evaluar-mejorar es el mismo ciclo para un gráfico, una sonificación o una fisicalización.
Más allá de los gráficos, hay otras dos formas de dar cuerpo a los datos. La sonificación los traduce en sonido —cada variable se vuelve tono, ritmo o volumen— y deja que el oído detecte patrones que el ojo pasa por alto. La fisicalización los traduce en objetos: maquetas, relieves para personas ciegas, estructuras que reproducen el impacto de un terremoto. Las dos se trabajan a fondo en las cápsulas técnicas más adelante.
Un aspecto crucial en esta fase es la preparación de los datos. Aunque escribir código o utilizar software gráfico es importante, gran parte del tiempo de implementación se dedica a preparar los datos para que sean adecuados para la visualización. Esto incluye tareas como la limpieza de los datos, donde se identifican y corrigen errores o datos faltantes, y la normalización de formatos para asegurar la coherencia en cómo se representan los datos, por ejemplo, asegurando que todas las fechas sigan el mismo formato o que las cifras monetarias estén en la misma moneda.
La ingeniería de datos es otra parte vital del proceso, donde los datos se transforman y organizan para garantizar que la visualización sea fiel y no distorsione la realidad que pretende representar. A menudo, durante la fase de diseño, se descubren problemas en los datos, como la presencia de lagunas o errores evidentes, lo que obliga a revisarlos y corregirlos antes de poder continuar con la visualización.
La evolución de una visualización durante la fase de implementación suele ser un proceso iterativo, lo que a menudo requiere regresar a la fase de diseño. Se empieza con ideas preliminares que se refinan a medida que se avanza, lo que puede implicar revisar los bocetos originales o ajustar el código o el diseño gráfico en función de nuevas percepciones o necesidades.
Evaluación
La fase de evaluación cierra cada vuelta del ciclo: una vez implementada la visualización, hay que recoger sistemáticamente las impresiones y juicios de usuarios para validar la calidad del artefacto. Sin esa retroalimentación, "iterar" se vuelve sólo retoque cosmético sin guía.
Las técnicas concretas — think-aloud, cronometraje de tareas, métricas de eficacia/eficiencia, cuestionarios psicométricos sobre claridad / utilidad / belleza — se discuten en detalle en la cápsula evalua. Acá basta con retener tres ideas: (a) prueba con usuarios no expertos, no con los autores del gráfico; (b) diseña tareas no triviales que obliguen a usar la visualización de verdad; (c) mide, no opines — el dato cualitativo del think-aloud combinado con el cuantitativo del cuestionario es la base mínima.
Mejoramiento
Con los resultados de la evaluación en mano, la visualización se modifica para corregir los puntos débiles detectados. Idealmente, el ciclo se repite hasta que los usuarios demuestren que pueden usar la visualización con autonomía para adquirir información nueva. Las heurísticas concretas para guiar el rediseño — desde la lista de Zuk-Carpendale hasta el mantra de Shneiderman — se tratan en la cápsula pensando.
El desafío de fondo es siempre el mismo: encontrar el equilibrio entre innovación (un diseño que aporte algo nuevo, que intrigue) y convención (un diseño que el lector pueda decodificar sin manual de instrucciones). Y al final, recordar que iterar nunca termina del todo: una visualización está "lista" sólo en relación con el ciclo de evaluación que la juzgó.
Una imagen para cerrar, a modo de anticipo: estos mecanismos de LEGO Technic (Fig. 12.5) son una de las herramientas con las que, más adelante, vas a dar cuerpo físico a los datos. Cuando llegues ahí, el ciclo será harto parecido al que acabas de recorrer.

Visualización multisensorial: terremotos de Chile en imagen, sonido y forma

¿Cuántos sentidos usan para procesar información? ¿Solo los ojos? Hoy vemos un terremoto en Chile desde el 2000, contado visual, sonora, y físicamente.
Hasta acá, casi todo lo que vimos entraba por un solo canal: los ojos. Pero mirar no es la única manera de procesar información — también se puede escuchar y tocar. Esta cápsula lo demuestra con un único proyecto: los terremotos de Chile desde el año 2000, vueltos imagen, sonido y objeto físico.
Una “visualización” multisensorial
📍 Nota de lectura. Esta cápsula es un adelanto de hacia dónde vamos en este curso. Verás aquí — en un solo proyecto integrador — los tres canales que desarrollaremos por separado más adelante: visualización interactiva, sonificación y fisicalización. No te preocupes si no entiendes todos los detalles técnicos: aquí lo importante es ver para qué sirve todo esto y mantenerse motivado. Volveremos sobre cada pieza con la teoría completa.
Los datos provienen del listado de terremotos de Chile en Wikipedia, integrados en una plataforma que combina varias formas de interacción sensorial en una sola experiencia.
🖱️ Esto no es una captura: es en vivo. Lo que viene es la visualización interactiva embebida aquí mismo. Pasa el cursor sobre un terremoto para ver su magnitud y fecha; haz clic para escucharlo. Prueba primero con el más grande del mapa y después con uno pequeño — vas a oír la diferencia antes de leer un solo número.
En esta visualización interactiva (Fig. 13.1) la vista y el oído se reparten el trabajo: la vista ubica dónde y cuándo ocurrió cada sismo; el oído comunica al instante la diferencia entre un temblor moderado y uno catastrófico.
La sonificación es lo que transforma el dato en experiencia: leer "magnitud 8,8" no impresiona; oír el estruendo correspondiente, sí.
🏠 El tercer canal: una casa que de verdad tiembla. A la imagen y al sonido se suma un objeto físico: una casita de LEGO montada sobre un servomotor. Haces clic en un terremoto del mapa y la casita se sacude; si el sismo es de los grandes, se derrumba. Ningún gráfico transmite el caos de un terremoto como verlo tirar abajo una casa.
Esa casita de LEGO (Fig. 13.2) está conectada a la misma plataforma: traduce la magnitud en una sacudida real y, en los terremotos más intensos, llega a derrumbarse por completo:

La fisicalización es la capa más visceral de las tres: ver una estructura sacudirse y caer convierte el daño en algo que se entiende con el cuerpo, no sólo con la cabeza.
Este enfoque multisensorial facilita una comprensión más profunda de los eventos sísmicos: al involucrar la vista, el oído y el tacto a la vez, ofrece una experiencia inmersiva que va más allá de los datos puramente visuales.
Y ojo: la casita es solo un ejemplo. Cada semestre los estudiantes arman sus propias visualizaciones multisensoriales —con los datos que ellos mismos eligen— y casi ninguna se parece a otra. Hay harta variedad. Este video recorre los proyectos del semestre 2025-II:
Tipos de datos: numéricos, ordinales y nominales

¡Silencio clase! Antes de dibujar, entiendan su dato. Si cuentan (1, 2, 3 perros), es Discreto. Si miden (temperatura, peso), es Continuo. No los mezclen.
Tipos de Datos y Escalas Asociadas
En estadística, los datos se pueden clasificar en diferentes categorías según sus características y la forma en que se pueden analizar. Los tres tipos principales son: datos numéricos (cuantitativos), datos ordinales y datos nominales (categóricos).
Datos Numéricos y sus Escalas
Los datos numéricos representan cantidades o valores medibles y son fundamentales para realizar operaciones matemáticas como la suma, la resta, la multiplicación y la división. Se distinguen por dos dimensiones independientes: el tipo de valor (discreto vs continuo) y la escala de medición (intervalo vs razón).
🌡️ ¿Un día de 30 °C es el doble de caluroso que uno de 15 °C? Responde mentalmente antes de seguir. Parece aritmética de primaria —30 es el doble de 15— pero la respuesta correcta depende de la escala con la que se mide, no de los números. Lo que viene explica por qué.
-
Por tipo de valor — discretos vs continuos
- Datos Discretos: valores numéricos que pueden contarse y suelen tomar valores enteros, sin intermedios. Por ejemplo, el número de estudiantes en una clase es un dato discreto, ya que solo se pueden tener valores enteros como 20 o 21, sin fracciones o decimales.
- Datos Continuos: pueden tomar cualquier valor dentro de un rango continuo, lo que permite mayor precisión al incluir decimales. Ejemplos comunes incluyen la altura, el peso o el tiempo, donde los valores pueden ser tan detallados como 1.75 metros de altura o 68.2 kilogramos de peso.
-
Por escala de medición — intervalo vs razón
Esta segunda dimensión determina cómo se interpretan los datos y qué operaciones matemáticas son aplicables.
- Escala de Intervalo: los datos tienen un orden y una distancia significativa entre valores, pero carecen de un "cero absoluto" que represente una ausencia total de la cantidad medida. Aunque podemos decir que una temperatura de 30 °C es 10 °C mayor que 20 °C, no podemos afirmar que 30 °C sea "el doble de caliente" que 15 °C. Ejemplos: temperaturas en Celsius o Fahrenheit, fechas en un calendario.
- Escala de Razón: sí tiene un cero absoluto, lo que permite no solo comparar diferencias entre valores sino también realizar afirmaciones de proporcionalidad. En el caso del peso, un objeto que pesa 10 kg es dos veces más pesado que uno de 5 kg. Ejemplos: altura, peso, longitud, conteos.
Cuatro mini-ejemplos resumen la distinción (Fig. 14.1): a la izquierda dos casos de intervalo (temperatura en °C, cociente intelectual) y a la derecha dos casos de razón (peso en kilos, número de alumnos en una clase). Solo en los dos de la derecha tiene sentido decir "el doble" o "la mitad", porque el cero significa "nada".

Datos Categóricos y sus Escalas
Los datos categóricos clasifican elementos en grupos o categorías. No se cuantifican numéricamente, sino que se organizan según características distintivas. Se distinguen dos subtipos según si la clasificación tiene un orden inherente o no:
-
Datos Ordinales y su Escala
Los datos ordinales permiten clasificar elementos en una jerarquía o secuencia con un orden inherente. La escala ordinal se usa para medir estos datos, permitiendo establecer un orden, aunque sin cuantificar la magnitud exacta de la diferencia entre los elementos.
- Ejemplo de Datos Ordinales: clasificaciones de satisfacción del cliente (insatisfecho, neutral, satisfecho). Podemos ordenar estas categorías de menor a mayor satisfacción, pero no podemos determinar exactamente cuánto mayor es "satisfecho" respecto a "neutral".
- Características de la Escala Ordinal: permite el ordenamiento de las categorías, pero no soporta operaciones matemáticas como la suma o la resta debido a la falta de intervalos uniformes entre las categorías.
- Aplicación de la Escala Ordinal: es útil en situaciones donde se necesita una jerarquía o ranking, como en encuestas de opinión o niveles de educación.
-
Datos Nominales y su Escala
Los datos nominales clasifican elementos en categorías distintas, sin ningún tipo de orden o jerarquía. La escala nominal mide estos datos, enfocándose en la clasificación sin establecer relaciones de orden.
- Ejemplo de Datos Nominales: género (masculino, femenino, no binario), colores (rojo, azul, verde), marcas de automóviles (Toyota, Ford, BMW). Estas categorías son mutuamente excluyentes: cada elemento solo puede pertenecer a una categoría específica.
- Características de la Escala Nominal: permite la clasificación, pero no soporta operaciones matemáticas ni establece un orden entre las categorías. Se utiliza principalmente para etiquetar y diferenciar elementos.
- Aplicación de la Escala Nominal: comúnmente se representan en tablas de frecuencia o gráficos de barras, útiles para visualizar la distribución de categorías y segmentar datos.
🎨 El color delata el orden. En la próxima figura, mira primero sólo los colores, sin leer las etiquetas. Donde veas una rampa —de claro a oscuro— hay harto orden en el dato: es ordinal. Donde veas tonos distintos sin gradación, no hay jerarquía: es nominal. El color no es decoración: es la primera pista del tipo de dato.
La diferencia entre las dos escalas se vuelve evidente cuando se comparan ejemplos (Fig. 14.2): a la izquierda, datos ordinales (nivel de educación, experiencia laboral) usando una rampa secuencial de colores que refuerza visualmente la jerarquía; a la derecha, datos nominales (marcas de smartphone, medios de transporte) usando tonos categóricos distintos sin que ninguno sugiera estar "antes" o "después" del otro.

Escalas en visualizaciones: lineal, log, porcentual, ordinal y temporal

En la escala de Intervalo, el cero es una convención (como 0 °C). En la escala de Razón, el cero es la ausencia total (como 0 kilos o 0 euros). Si confundes esto, las proporciones fallan.
Escalas en las visualizaciones de datos
Las escalas en un gráfico son fundamentales para interpretar correctamente los datos. Sirven para mapear valores de datos a posiciones en un gráfico, proporcionando una referencia visual que permite al espectador entender la magnitud, proporción y relación entre los datos. El esquema (Fig. 15.1) resume los principales tipos de escala que se usan en visualización.

Escala lineal. En una escala lineal, la distancia visual entre dos puntos en cualquier parte del eje es constante. Esto significa que los incrementos entre los valores son uniformes, sin importar si los valores se encuentran en el extremo bajo o alto de la escala. Esta escala es ideal cuando se desea una representación directa y proporcional de los datos, permitiendo comparaciones simples entre valores numéricos.
📏 La escala que rescata a los pequeños. Cuando los datos abarcan un rango harto amplio, una escala lineal aplasta los valores chicos contra el cero —quedan ilegibles— mientras los grandes se reparten todo el eje. La escala logarítmica comprime ese rango y vuelve a hacer visibles a los pequeños. La próxima figura compara las dos escalas con la población de los estados de EE. UU.
Escala logarítmica. A diferencia de la lineal, una escala logarítmica comprime los valores a medida que aumentan: cada paso del eje no suma una cantidad fija, sino que la multiplica. Es menos común y menos intuitiva para quien no trabaja a diario con datos, pero indispensable cuando un dato abarca varios órdenes de magnitud (Fig. 15.2).

Escala de porcentajes. Esta escala tiene un máximo fijo del 100% cuando se utiliza para representar partes de un todo. Es fundamental en visualizaciones como gráficos de pastel (pie charts), donde la suma de todas las partes debe ser igual a 100%. El uso incorrecto de esta escala, como mostrar un gráfico donde la suma excede el 100%, puede llevar a confusión y a errores de interpretación.
Escala categórica. Esta escala se utiliza para representar datos no numéricos, organizando diferentes grupos o categorías. No existe un orden inherente entre las categorías a menos que se trate de datos ordinales. Por ejemplo, un gráfico de barras puede usar una escala categórica en el eje horizontal (para mostrar diferentes grupos o categorías) y una escala numérica en el eje vertical (para mostrar los valores correspondientes a esas categorías).
Escala ordinal. En el caso de los datos ordinales, donde las categorías tienen un orden específico (como una escala de satisfacción de "horrible" a "excelente"), es importante mantener ese orden en la visualización para facilitar la comparación, como ilustra el ejemplo (Fig. 15.3) con una escala ordinal en el eje X y una escala lineal en el eje Y.

Escala de tiempo. El tiempo es una variable continua que generalmente se representa en una escala lineal, pero también puede dividirse en categorías como años, meses o días de la semana, permitiendo visualizarlo como una variable discreta. También una escala de tiempo puede tener una naturaleza cíclica (por ejemplo, hay un mediodía, un sábado, y un enero cada año), lo que permite representar datos para que muestren patrones temporales recurrentes. Dado que el tiempo es una parte fundamental de la vida diaria, su representación en visualizaciones proporciona un contexto familiar y fácilmente comprensible para el público.
Estas escalas son fundamentales para elegir cómo representar los datos en visualizaciones, dependiendo de las características de los datos y de la historia que se desea contar.
Valores absolutos vs. valores relativos: cuándo normalizar
Una decisión de escala que pasa fácilmente desapercibida pero que cambia radicalmente la lectura de un gráfico es si los valores se muestran en términos absolutos o en términos relativos (por habitante, por unidad de tiempo, como porcentaje de algo). A menudo es más útil mostrar valores relativos para contextualizar la información en función de factores relevantes — y evitar conclusiones engañosas.
🚨 ¿Cuáles son las ciudades más peligrosas? Piensa en un par antes de seguir. Si se te vinieron a la mente las grandes —Chicago, Nueva York—, cuidado: ése es el ranking por número total de crímenes, y las ciudades grandes lo encabezan sólo por ser grandes. La próxima figura muestra qué pasa cuando se mide por habitante.
La comparación entre rankings (Fig. 15.4) lo deja claro: en el gráfico de la derecha, ordenado por número absoluto de asesinatos, ciudades grandes como Chicago, Nueva York, Los Ángeles y Filadelfia aparecen como las más peligrosas; pero al relativizar los datos por cada 100.000 habitantes, el gráfico de la izquierda muestra una composición del ranking radicalmente distinta.

Lo mismo vale para los mapas. Si vamos a visualizar un fenómeno o un valor específico relacionado con los habitantes en diferentes localidades, es importante relativizar los datos al número de habitantes. El mapa coroplético (Fig. 15.5) lo muestra: las áreas sin población quedan en blanco (sin valor), evitando el sesgo de mostrar áreas vacías como si no tuvieran fenómeno relevante.

Esta viñeta humorística (Fig. 15.6) lo recuerda con un chiste: ciertos fenómenos (crímenes, enfermedades, accidentes) sólo pueden ocurrir donde hay personas. Si no ajustamos los datos según la población, podemos obtener conclusiones engañosas, porque una localidad sin habitantes no tendrá eventos registrados simplemente porque no hay nadie para experimentar esos fenómenos.

La regla, en todos los casos, es la misma: cuando un fenómeno depende del tamaño de la población, hay que mostrarlo en términos relativos —no absolutos—, o el gráfico contará una historia equivocada.
Sistemas de coordenadas y jerarquía de señales visuales (Cleveland & McGill)

Situar el dato en el vacío requiere un Sistema de Coordenadas: Cartesiano, Polar, Geográfico. Y recuerda la jerarquía: la Posición en el eje común es lo que el humano lee mejor.
El sistema de coordenadas en la visualización de datos
Los sistemas de coordenadas proporcionan un marco estructurado para situar y dar significado a los datos representados gráficamente. Los tres sistemas más comunes (Fig. 16.1) son el cartesiano (el más usado), el polar (en gráficos circulares como los de pastel) y el geográfico (para representar posiciones en un mapa).

El sistema cartesiano es el más utilizado y familiar en visualizaciones de datos, como gráficos de barras o gráficos de dispersión. En este sistema, las coordenadas se representan con pares (x, y) en un plano, lo que permite medir distancias y relacionar puntos de manera directa. Es ideal para representar relaciones lineales y comparaciones directas.
El sistema polar organiza los datos en un formato circular, donde las posiciones se determinan por ángulos y distancias desde un punto central. Este sistema es útil cuando el ángulo o la dirección son elementos clave en la interpretación de los datos, como en gráficos circulares o de radar.
El sistema geográfico utiliza coordenadas de latitud y longitud para mapear datos sobre la superficie de la Tierra.
Nota. En el sistema de coordenadas geográficas, los datos representados suelen ser la latitud y la longitud, que determinan la ubicación exacta de un punto en el espacio. Si sólo se utiliza la posición como señal visual, generalmente se limitan a estos dos parámetros. Para representar otros tipos de datos, como temperatura o población, es necesario incorporar señales visuales adicionales — color, área o forma — que proporcionen información más allá de la ubicación geográfica.
Es esencial para visualizar datos relacionados con ubicaciones geográficas, proporcionando una conexión inmediata con el mundo físico. Sin embargo, la representación de datos geográficos en un plano bidimensional requiere de proyecciones, cada una con sus propias ventajas y desventajas, como la conservación de ángulos o áreas.
Señales visuales
En la visualización de datos, las señales visuales juegan un papel crucial al mapear datos a geometría y color, ayudando a identificar patrones y realizar comparaciones. El catálogo (Fig. 16.2) reúne los principales tipos de señales visuales que detallamos a continuación.

Posición: En gráficos de dispersión y otros diagramas, la posición de un punto en el espacio se utiliza para comparar valores.
Nota. En una visualización, es muy inusual que la posición no se utilice para representar algún tipo de dato. Por ejemplo, incluso en un gráfico de barras verticales, donde la longitud de la barra se suele utilizar para comparar valores, la posición también juega un papel importante: lo relevante es la posición del extremo superior de la barra en el eje vertical, y la posición en el eje horizontal codifica las distintas categorías o valores que se comparan.
La ubicación en el sistema de coordenadas determina la representación de cada dato. Usar sólo la posición es eficiente en términos de espacio, pero puede ser difícil identificar la información específica de cada punto, especialmente cuando hay una gran cantidad de datos.
Nota. La posición no se limita sólo al sistema cartesiano: es una señal visual válida en otros sistemas. En polar la posición está determinada por el ángulo y la distancia desde el centro; en geográfico, por la latitud y la longitud.
Longitud: En gráficos de barras, la longitud de cada barra representa el valor absoluto de un dato. La longitud puede ser horizontal, vertical o angular. Es importante asegurarse de que el eje de longitud comience en cero para evitar distorsiones en la percepción de los datos, ya que una escala mal configurada puede exagerar o minimizar las diferencias entre valores.
Ángulo: En gráficos circulares (o de pastel), el ángulo de cada sector representa una fracción del total. Los ángulos permiten visualizar la proporción de cada categoría en relación con el total, haciendo evidente la parte que cada categoría representa del conjunto completo.
Dirección: Similar al ángulo, pero enfocado en la orientación de un vector dentro de un sistema de coordenadas. La dirección permite analizar tendencias, cambios y fluctuaciones en los datos a lo largo de un periodo de tiempo o en diferentes condiciones.
Formas: Empleadas para diferenciar categorías, especialmente en mapas o gráficos. Las formas pueden ofrecer un contexto adicional al representar elementos específicos.
Área y volumen: Estas señales representan datos con tamaño en dos dimensiones (área) o tres dimensiones (volumen). Asegurarse de que el tamaño refleje con precisión los valores es crucial; por ejemplo, aumentar el tamaño de un cuadrado o un cubo debe tener en cuenta las proporciones correctas para evitar distorsiones en la comparación de datos (ver cápsulas anteriores).
Color: el color se utiliza para diferenciar categorías o codificar magnitudes a través de tres dimensiones independientes — tono, saturación y brillo. Estas tres dimensiones, junto con las cuestiones de accesibilidad (daltonismo), uso del color como ruido vs información, y consistencia cromática entre gráficos relacionados, se tratan a fondo en la Cápsula 10 (El color en InfoVis).
🎯 No todas las señales se leen igual de bien. La próxima figura muestra el mismo conjunto de valores codificado de varias maneras —posición, longitud, ángulo, área, color—. Recórrelas y fíjate en cuál puedes leer las cifras casi sin esfuerzo y en cuál tienes que estimar a ojo. La diferencia no es cuestión de gusto: está harto medida.
Quien la midió fue un estudio de 1985 de William Cleveland y Robert McGill: clasificaron la precisión con la que se lee cada señal —todas menos las formas— y el ranking resultante (Fig. 16.3) las ordena de la más precisa, la posición en una escala común, a la menos, el color y la densidad.

Por ejemplo, los gráficos de barras se clasificaron como más precisos que los gráficos de pastel, mientras que los mapas de calor quedaron en la parte inferior. La eficiencia y exactitud no son los únicos objetivos de la visualización de datos, por lo que las clasificaciones deben considerarse como una guía general en lugar de reglas estrictas.
Multidimensionalidad: cómo mostrar 3, 4 o más variables a la vez

¿Cómo metes cinco dimensiones en un gráfico plano? Usa Posición X, Posición Y, Color, Tamaño y Forma. Y si necesitas diez, bienvenido a las Coordenadas Paralelas.
Multidimensionalidad en la Visualización de Información
La multidimensionalidad permite representar muchas variables en un solo gráfico, o en un conjunto de gráficos relacionados. Veámoslo con tres técnicas.
🔢 Un punto puede cargar cinco variables. Empieza con un punto sobre un eje: una dimensión. Súbelo a un plano X-Y: van dos. Ahora píntalo —tres—, agrándalo —cuatro— y cámbiale la forma —cinco. Sin salir de un solo gráfico, cada punto llega a codificar cinco variables a la vez.
Ese es el gráfico de puntos multidimensional (Fig. 17.1). Pero atención a algo que vimos en la cápsula anterior: esos cinco canales no se leen igual de bien. La posición es la señal más precisa; el área y la forma, de las menos. Por eso conviene reservar las dos variables más importantes para los ejes X e Y, y dejar el color, el tamaño y la forma para las secundarias.

Gráfico de coordenadas paralelas. Cuando las dimensiones son demasiadas para los canales de un solo punto —diez, veinte—, las coordenadas paralelas le dan a cada dimensión su propio eje vertical; cada objeto se vuelve una línea quebrada que los cruza todos, y los patrones aparecen en el haz de líneas.
Múltiples gráficos para diferentes combinaciones de dimensiones. Los gráficos múltiples (Fig. 17.2) muestran diferentes combinaciones de dimensiones a través de una serie de gráficos relacionados. Por ejemplo, se pueden crear gráficos separados para cada combinación posible de variables, como un gráfico de dispersión para dos dimensiones y un gráfico de barras para otra dimensión, permitiendo al lector comparar y contrastar cómo diferentes variables se relacionan entre sí. Esto también puede incluir paneles que muestran diferentes subconjuntos de datos o representaciones, facilitando una comprensión más detallada de cómo cada dimensión afecta a las demás.

Estos enfoques permiten una representación multidimensional de los datos, facilitando la identificación de patrones, tendencias y relaciones complejas.
Puntos de vista: dos formas de ver las mismas N dimensiones
🌹 El mismo dato, dos preguntas opuestas. Tienes un conjunto con muchas dimensiones. ¿Quieres retratar un objeto —ver a un alumno entero, materia por materia— o comparar muchos objetos entre sí? La rosa de Nightingale hace lo primero; las coordenadas paralelas, lo segundo. Ninguna es mejor: la pregunta decide cuál.
La rosa de Nightingale (Fig. 17.3) trata cada objeto (cada alumno, en el ejemplo escolar de la Cápsula 05) como una forma circular compacta: cada materia es un pétalo, y el ojo capta la entidad-alumno entera de un vistazo. Esta técnica es óptima cuando se quiere caracterizar un objeto individual en sus hartas dimensiones — pero no facilita la comparación entre objetos distintos.
Las coordenadas paralelas (Fig. 17.4), en cambio, son óptimas para lo contrario: comparar el comportamiento de muchos objetos en una misma dimensión, o buscar correlaciones entre dimensiones. Su punto débil es que la identidad de cada objeto se diluye en el haz de líneas; la variante coloreada por objeto (Fig. 17.5) intenta recuperar parte de esa visibilidad con el color.
Estas dos técnicas no se eligen por preferencia personal, sino según el contexto y la pregunta del lector, como se discutió en detalle en la Cápsula 05 (El contexto manda — Puntos de vista). Lo importante es que ambas —junto con las técnicas de la primera sección, puntos 5D y gráficos múltiples— resuelven el mismo problema: mostrar muchas dimensiones a la vez.
Más allá de "qué técnicas existen", está la pregunta operativa: ¿cuál de éstas elijo en un caso concreto? Es un tema en sí —vocabulario visual, mapeo pregunta → gráfico, uso de LLMs como asistentes— y se trata en la cápsula siguiente, Cómo elegir la visualización adecuada.
Cómo elegir la visualización adecuada: vocabulario visual, pregunta primero, ayuda de LLMs

Empieza por la pregunta, no por el gráfico. Si no puedes escribir la pregunta en una frase, ningún gráfico la va a responder por ti. Y si te trabas, pídele ayuda a un LLM — pero cuéntale qué datos tienes y qué quieres saber.
Esta cápsula es el punto de inflexión entre "qué técnicas existen" (Cápsulas 13-16) y "cómo construyo una visualización efectiva" (Cápsulas 18+). Aquí vemos cómo elegir entre el repertorio disponible.
Vocabulario visual: el catálogo del oficio
Crear visualizaciones efectivas puede parecer una tarea desafiante, pero el uso de un vocabulario visual puede simplificar mucho este proceso. Un vocabulario visual es un conjunto de tipos de gráfico ya validados por la comunidad, cada uno asociado a una clase de pregunta o de dato. Tener este catálogo a mano evita reinventar la rueda cada vez.
Un buen punto de partida es el Visual Vocabulary del Financial Times, que organiza ~70 tipos de gráfico en 9 familias según la "intención" comunicativa: desviación, correlación, ranking, distribución, parte-de-un-todo, etc. No memorices la lista — úsala como diccionario cuando estés diseñando.
Un esquema general para crear visualizaciones puede seguir una receta sencilla:
- Identifica la pregunta que quieres responder con el gráfico.
- Determina los tipos de datos que tienes (numéricos, categóricos, temporales, geográficos — ver Cápsula 13).
- Selecciona el tipo de gráfico apropiado para esa pregunta y esos datos.
- Aplica las escalas correctas (lineal, log, ordinal, ver Cápsula 14).
- Asigna señales visuales (posición, longitud, ángulo, color, ver Cápsula 15).
Sin embargo, esta receta es un punto de partida, no una camisa de fuerza. La verdadera creatividad en visualización surge de explorar más allá de las recomendaciones estándar y adaptar las técnicas al contexto único de cada proyecto. Flexibilidad en la aplicación de las directrices lleva a soluciones más innovadoras y a visualizaciones que no sólo transmiten información con claridad, sino que también cautivan al espectador.
Empezar siempre desde la pregunta
Una visualización es, en el fondo, una historia contada con datos — y toda historia arranca de una pregunta. Los números son el material; el gráfico, la forma de la respuesta. Por eso una narrativa de datos no consiste en adornar cifras, sino en usar un gráfico para responder algo concreto.
❓ Seis preguntas que vuelven una y otra vez. El gráfico que necesitas depende de la pregunta que le haces a los datos — así que empieza por nombrarla en una frase. Hay seis preguntas que aparecen con muchísima frecuencia: están lejos de cubrir todo lo que se puede preguntar, pero si la tuya se parece a una de ellas, el tipo de gráfico casi se elige solo.
El esquema (Fig. 18.1) reúne esas seis, cada una con su concepto estadístico y el tipo de gráfico que la responde:

- ¿Cuál ___ es el mejor y el peor? — Concepto: Máximos y mínimos. Identifica los valores extremos en un dataset (típicamente con un bar chart ordenado).
- ¿Cómo ha cambiado ___ a lo largo del tiempo? — Concepto: Patrones temporales. Explora la evolución en función del tiempo (típicamente con un line chart).
- ¿Qué ___ se destaca del resto? — Concepto: Outliers (valores atípicos). Detecta valores que no se ajustan a los patrones esperados (típicamente con un scatter plot).
- ¿Qué hace que ___ sea diferente de ___? — Concepto: Clustering. Identifica grupos con características similares (típicamente con scatter + clustering).
- ¿Cómo están relacionados ___ y ___ entre sí? — Concepto: Correlación. Establece relaciones entre dos variables (típicamente con un scatter plot con línea de tendencia).
- ¿Cuál es la descomposición de ___? — Concepto: Distribuciones. Muestra cómo se distribuyen los datos en categorías o rangos (típicamente con un histograma o un boxplot).
Pídele ayuda a un LLM (pero háblale bien)
Una herramienta práctica que en los últimos años cambió el juego: los modelos de lenguaje grandes (ChatGPT, Claude, Gemini, Mistral, etc.). Son extraordinariamente buenos para sugerir el tipo de gráfico adecuado dado un conjunto de datos y una pregunta — siempre que tú sepas hacer la pregunta correcta.
La conversación típica que funciona:
Tú: "Tengo una tabla con 50 filas: cada fila es un país, y las columnas son población (numérica), PIB per cápita (numérica), continente (categórica) y porcentaje de población urbana (numérica de 0 a 100). Quiero mostrar si los países con más PIB per cápita tienden a ser más urbanos, separando por continente. ¿Qué tipo de gráfico me recomiendas?"
LLM: "Un scatter plot con color por continente sería ideal. Eje X: PIB per cápita (escala logarítmica, porque los valores cubren varios órdenes de magnitud). Eje Y: % urbano. Color: continente. Tamaño opcional del punto: población. Para ver si la relación se mantiene dentro de cada continente, puedes además agregar líneas de tendencia por color."
Tres reglas para que el LLM te dé buenas respuestas:
- Describe los datos con precisión — cuántas filas, qué columnas, qué tipo (numérica continua / discreta / categórica nominal / ordinal / temporal / geográfica). Sin esta información el LLM tiene que adivinar y suele acertar menos.
- Describe la pregunta con verbos concretos — comparar, clasificar, mostrar evolución, destacar outliers, encontrar correlación. No le digas "quiero un gráfico bonito"; eso lo lleva al cliché.
- Pídele alternativas — "dame tres opciones, ordenadas de la más simple a la más rica". El LLM tiende a recomendar la opción más sofisticada por defecto; pidiendo opciones te das harto margen para elegir.
El LLM no reemplaza a tu juicio — pero te ahorra horas de catálogo. Es como tener un colega senior que conoce todos los gráficos y te recuerda los principios del curso cuando se los pides.
Exploratorio vs explicativo: el contexto, el quién, el qué y el cómo

El diseño Exploratorio es buscar en cien ostras para encontrar perlas. El diseño Explicativo es mostrarle al cliente SOLO esas dos perlas.
Quién, qué y cómo en el análisis explicativo
Antes de profundizar en el concepto de contexto, es importante distinguir entre análisis exploratorio y análisis explicativo.
El análisis exploratorio es el proceso que se realiza para comprender los datos y descubrir qué aspectos podrían ser relevantes o interesantes para destacar. Durante este tipo de análisis, se examinan los datos desde diferentes perspectivas, formulando múltiples hipótesis y pruebas, como si se estuvieran buscando perlas en ostras (Fig. 19.1).

Es posible que haya que abrir 100 ostras —es decir, probar 100 hipótesis o analizar los datos de 100 maneras diferentes— para encontrar quizá dos perlas (Fig. 19.2).

En cambio, cuando llega el momento de comunicar nuestros hallazgos al público, debemos estar en el espacio del análisis explicativo. Esto significa que tenemos un mensaje específico que queremos transmitir, una historia concreta que queremos contar, probablemente relacionada con esas dos perlas que encontramos.
Dos formas de mirar los mismos datos
La diferencia fundamental entre el científico de datos (exploratorio) y el diseñador (explicativo) es dónde dirigen la atención. Frente al mismo conjunto de puntos, ven cosas distintas: para el científico cada punto es un posible hallazgo y ninguno se destaca todavía; para el diseñador unos pocos puntos ya fueron declarados "perla" y el resto se atenúa para no distraer.
El error común es pensar que está bien mostrar el análisis exploratorio tal como es (presentar todos los datos, todas las 100 ostras) cuando en realidad deberíamos estar mostrando el análisis explicativo (transformando los datos en información que el público pueda consumir: las dos perlas). Es un error comprensible. Después de realizar un análisis completo, puede ser tentador querer mostrar todo el trabajo realizado para demostrar la solidez del análisis. Sin embargo, hay que resistir esta tentación. Al hacerlo, estarías obligando a tu audiencia a volver a abrir todas las ostras. En lugar de eso, enfócate en las perlas, en la información que realmente necesita conocer tu audiencia.
El contexto es clave
Tu audiencia no abrió las cien ostras contigo. Sin tu contexto, no puede distinguir la perla del montón.
Tú pasaste hartas horas con los datos. Tu audiencia tiene 30 segundos. El contexto es la diferencia entre que entienda o no.
El contexto en Visualización de Datos
Más allá del concepto general visto en cápsulas anteriores, en la práctica el contexto de una visualización se concreta en la información adicional que ayuda a responder el quién, qué, cuándo, dónde y por qué de los datos. No vive sólo en títulos y subtítulos: también incluye anotaciones gráficas que destacan partes específicas del gráfico, iconos o formas que orientan al lector, y la elección de sistemas de coordenadas, escalas y señales visuales que ya por sí mismas anclan el dato a un marco familiar. Un mapa coroplético contextualiza en el espacio físico; una escala temporal en años contextualiza en la memoria reciente; un título descriptivo orienta, uno accionable directamente pide una decisión.
El contexto puede ser explícito (etiquetas en los ejes, descripciones detalladas, anotaciones) o implícito (basado en la familiaridad del público con el tema, o en convenciones visuales que se asocian naturalmente con ciertos significados — verde es bueno, una flecha hacia arriba es crecimiento). Lo importante: un gráfico sin contexto es una colección de pixeles abstractos; un gráfico con el contexto justo se convierte en una herramienta de comprensión.
En el análisis explicativo, es fundamental reflexionar y ser extremadamente claro en tres preguntas que retomamos de la Cápsula 05 (El contexto manda): Quién (a quién te diriges — analista, paciente, ciudadano, inversor), Qué (qué quieres que tu audiencia sepa o haga concretamente) y Cómo (qué datos usas para reforzar el mensaje). Son las mismas preguntas que ya vimos como definitorias del contexto en general; lo nuevo aquí es aplicarlas operativamente al rediseño de un gráfico específico — qué información agregar, qué destacar, qué borrar.
El tono también importa. ¿Estás celebrando un logro? ¿Motivando a la acción? ¿El tema es ligero o serio? El tono elegido influirá en decisiones de diseño como los colores, la tipografía y el tipo de interactividad. Define el tono desde el principio para asegurar que todas las decisiones de diseño estén alineadas con tu objetivo.
Quién, Qué y Cómo con ejemplos
Veamos el quién, el qué y el cómo en acción, sobre dos casos — cada uno comparando una versión cruda con su rediseño.
Este gráfico de barras muestra los tickets recibidos y procesados a lo largo del año (Fig. 19.3): al final hay una brecha creciente entre ambas series, pero el gráfico no le dice al lector qué se espera que haga con ese dato.
El rediseño, en cambio, sí responde a las tres preguntas (Fig. 19.4): mismo dato, pero ahora con un destinatario claro, un pedido concreto y una manera de demostrarlo.
Pasemos a otro caso. Una encuesta sobre interés en la ciencia, presentada como dos gráficos de pastel lado a lado (Fig. 19.5), recoge opiniones antes y después de un programa educativo; pero comparar las dos tortas obliga al lector a hacer aritmética visual.

El rediseño como slope chart (Fig. 19.6) responde el mismo tridente y, de paso, vuelve legible de un vistazo lo que dos pasteles escondían.

🎯 El patrón del rediseño explicativo. Los dos casos siguen la misma receta. Responde las tres preguntas —quién lee, qué quieres que haga, cómo se lo muestras— y después cambia el título de descriptivo ("Ticket Trend", "Survey Results") a accionable ("Please approve the hire of 2 FTEs", "Pilot program was a success"). Es el cambio más barato y más poderoso del rediseño: mismo dato, mensaje claro.
Recuerda: en exploratoria es distinto
En una InfoVis exploratoria no es necesario resaltar ningún punto específico de la historia, ya que cada usuario (ej. científico de datos) construye su propia interpretación a través de la exploración. La flexibilidad en la exploración de datos permite descubrir insights y patrones por sí mismos, siempre y cuando se ofrezca suficiente contexto para facilitar su comprensión.
Lo que vimos en esta cápsula —resaltar las dos perlas, contextualizar el quién/qué/cómo, narrar con título y texto— vale principalmente para la explicativa. Cuando construyas un dashboard de exploración, deja que las herramientas (filtros, hover, zoom) hagan el trabajo.
Data-Ink ratio y atributos preatentivos: menos tinta, más mensaje

Menos es Más. Maximiza la proporción de tinta usada para datos (Data-Ink Ratio). Si una grilla distrae, bórrala. Si un color no aporta info, a la basura.
La excelencia gráfica según Tufte
Antes de hablar de cómo "borrar tinta", conviene fijar el horizonte: ¿hacia qué apunta una buena visualización? Tufte propone el concepto de excelencia gráfica como combinación de tres ingredientes que se sostienen mutuamente:
- Sustancia — una historia. Toda visualización debería tener un punto claro, una narrativa que el lector pueda seguir. La historia es lo que le da sentido a los datos y diferencia un gráfico útil de uno meramente decorativo.
- Estadística sólida. Los datos tienen que estar bien tomados, bien calculados, y la representación tiene que respetar su naturaleza. Una visualización elegante sobre datos incorrectos no es excelencia: es propaganda.
- Diseño elegante y eficiente. Elegancia aquí significa tres cosas concretas: claridad (el lector entiende sin esfuerzo), precisión (cada elemento gráfico es exacto y honesto) y eficiencia (la mayor cantidad de ideas en el menor tiempo, espacio y tinta posibles).
La eficiencia es el puente con los principios que vienen a continuación. La idea del "ink ratio" — la proporción de tinta dedicada a datos significativos versus tinta dedicada a decoración — es la que maximiza esa eficiencia. Tufte la sintetizó en un esquema famoso (Fig. 20.1): las ideas del autor se proyectan al lector a través del tiempo que éste dedica al gráfico, y se materializan en la tinta (ink) sobre el espacio disponible. La excelencia gráfica es maximizar la transferencia de ideas por unidad de tinta y de tiempo. Y por encima de los tres ingredientes, la excelencia gráfica también exige contar la verdad sobre los datos: presentación honesta y sin distorsiones, porque sin confianza no hay decisión bien tomada.

El cartel del baño — una analogía (con dibujito)
🚽 Antes de los gráficos, un cartel de baño. Sobre un W.C. público alguien pegó tres instrucciones bienintencionadas. La galería que sigue reconstruye, acto por acto, cómo un diseñador las va tachando hasta dejar sólo lo esencial. Fíjate qué se atreve a borrar — incluso lo que «parecía importante»: ahí está toda la cápsula en miniatura.
Haz clic en cada paso para seguir el razonamiento: Galería 20.1
Galería 20.1: El cartel del WC — del exceso a la elegancia
Cinco actos que reconstruyen el rediseño de un cartel real pegado sobre un W.C. público, tachando palabras redundantes hasta llegar a una versión breve. Es la analogía didáctica con la que abre la cápsula: antes de hablar de gráficos, el lector entiende qué quiere decir "borrar" y por qué el diseñador es el que se atreve a hacerlo, incluso cuando lo que borra "parecía importante".





Menos es Más: Cinco Principios para Maximizar la Eficiencia
A continuación, se detallan cinco principios clave para lograr una visualización gráfica sobresaliente:
- Mostrar los Datos: Este principio sostiene que la visualización debe centrarse en mostrar los datos de manera clara y directa, sin distracciones ni elementos superfluos. La esencia de la visualización debe ser la presentación efectiva de la información, permitiendo que los datos hablen por sí mismos.
- Maximizar la Relación Tinta-Datos Dentro de lo Razonable: Se refiere a la idea de aumentar la proporción de tinta utilizada para representar datos en relación con la tinta utilizada para otros elementos. Esto significa que la mayor parte del espacio en la visualización debe dedicarse a mostrar datos significativos, minimizando el uso de tinta para elementos decorativos o innecesarios. Sin embargo, esto debe hacerse con prudencia, asegurando que la claridad y la efectividad no se vean comprometidas.
- Eliminar la Tinta No Relacionada con los Datos Dentro de lo Razonable: Este principio implica eliminar cualquier tinta que no contribuya directamente a la representación de los datos. Esto incluye elementos decorativos, líneas, etiquetas o colores que no añaden valor a la comprensión de la información. La eliminación de tinta no esencial ayuda a evitar distracciones y a enfocar la atención en los datos relevantes, pero siempre manteniendo la legibilidad y la funcionalidad de la visualización.
- Eliminar la Tinta de Datos Redundante: Se refiere a la eliminación de elementos gráficos repetitivos o redundantes que no aportan información adicional. Esto incluye duplicaciones en la representación de datos o elementos gráficos que simplemente repiten lo que ya está claramente expresado en otras partes de la visualización. El objetivo es simplificar la visualización para mejorar la comprensión sin perder información importante.
- Revisar y Editar: Este principio destaca la importancia de revisar y ajustar la visualización para asegurar que cumpla con los estándares de excelencia gráfica. La revisión y edición implican ajustar detalles, eliminar errores y optimizar el diseño para mejorar la claridad, precisión y eficiencia de la visualización. Es un proceso continuo que busca perfeccionar la presentación de los datos.
Siguiendo estos principios, se puede crear una visualización de datos que no solo sea visualmente atractiva, sino también efectiva en la transmisión de información clave y en la facilitación de una comprensión rápida y precisa por parte del espectador. Veámoslos en acción aplicados a un caso real.
El bacon paso a paso — menos es más en acción
🥓 Doce versiones, un elemento borrado por vez. La próxima galería toma un bar chart real —calorías de comida chatarra— y le quita una cosa a la vez: la grilla, el borde, el relleno de color, las etiquetas redundantes… de la versión original recargada a la final, limpia. No es minimalismo por estética: es eficiencia comunicativa, cada píxel trabajando para el mensaje.
El gráfico quiere contar que el bacon (533 cal) pertenece al grupo "alto", junto a las papas fritas y lejos de la pizza. Haz clic en cualquier paso para verlo en grande: Galería 20.2
Galería 20.2: Transformación del gráfico bacon — paso a paso
Doce imágenes (vectoriales, extraídas directamente del PDF original de Darkhorse Analytics) que documentan el rediseño completo de un bar chart sobre calorías, eliminando un elemento a la vez. Aplicación práctica y exhaustiva del Data-Ink ratio: cada paso muestra cómo borrar pixel por pixel mejora la legibilidad y, sobre todo, demuestra que el rediseño no es minimalismo por estética sino eficiencia comunicativa.












Visualizaciones comunes (¡y efectivas!)
📊 Diez gráficos resuelven el 90 % de los casos. No hace falta inventar gráficos exóticos. La galería que sigue es un menú de los diez tipos que cubren casi todo en datos de negocio — y, para cada uno, cuándo conviene y dónde se equivoca la gente. Cuando dudes, elige de esta lista antes que de tu imaginación.
Lo más simple suele ser lo mejor: Galería 20.3
Galería 20.3: Tipos de visualización comunes — pros y contras
Diez tipos de visualización que cubren el 90 % de los casos en datos de negocio. Funciona como menú de referencia: en lugar de inventar gráficos exóticos, la cápsula muestra que con este catálogo se resuelve casi todo. Saber elegir bien dentro de un repertorio limitado es mucho más útil que conocer cien tipos distintos.










Resaltar un punto en la historia
En el contexto de la visualización de información explicativa, es fundamental utilizar estrategias de diseño que dirijan la atención del usuario hacia los puntos clave de la historia que se está presentando. Esto incluye el uso de colores distintivos para resaltar elementos importantes y de texto anotativo para proporcionar contexto adicional.
El ejercicio de los "3"
🔢 ¿Cuántos 3 hay en estos números? Vas a ver el mismo bloque de dígitos dos veces. En la primera imagen, cuenta los 3 a mano — vas a sufrir un poco. En la segunda, los 3 están en color: la respuesta te salta a la cara sin que la busques. Esa diferencia, sentida en tu propio cuerpo, es un atributo preatentivo.
Pruébalo tú mismo: Galería 20.4
Galería 20.4: ¿Cuántos 3 hay? — el efecto preatentivo del color
Dos imágenes con el mismo bloque de dígitos para que el lector experimente, en su propio cuerpo, qué es un atributo preatentivo. Es la prueba empírica que la cápsula necesita antes de recomendar el uso del color como guía: una vez que sientes la diferencia entre buscar consciente y "ver automáticamente", el resto de las reglas dejan de ser arbitrarias.


El color y el peso (la negrita) son justamente eso: atributos preatentivos que el cerebro detecta en milisegundos, sin esfuerzo consciente. Úsalos para llevar la atención del lector exactamente adonde quieres.
Aplicado a gráficos
🎨 El color, bien usado y mal usado. El experimento de los «3» se traslada ahora a gráficos de verdad — barras, líneas, slope charts. La galería muestra usos correctos del color para dirigir la mirada, y también dos contraejemplos rainbow: cuando todos los elementos gritan a la vez, ninguno guía.
Usos correctos y errores frecuentes: Galería 20.5
Galería 20.5: Resaltar en gráficos — color como guía
Cinco ejemplos con usos correctos e incorrectos del color como atributo preatentivo. Aplica lo aprendido en el experimento de los "3" al mundo real de las visualizaciones, e incluye dos contraejemplos arcoíris para que el lector vea, por contraste, qué pasa cuando el color se usa por moda en lugar de por significado.





Texto: tu mejor amigo
✍️ El texto guía tanto como el color. Existe el reflejo de pensar «primero el gráfico; el texto, si sobra lugar». Es un error: una anotación bien puesta, una palabra en negrita o un tamaño distinto dirigen la lectura con la misma fuerza que un color. La galería recorre esas técnicas tipográficas, una por una, con ejemplos.
Anotaciones, negrita, itálica, tamaño, jerarquías combinadas: Galería 20.6
Galería 20.6: El texto en visualización — tipos de énfasis
Siete ejemplos que demuestran que el texto es una herramienta tan poderosa como el color para guiar la atención. La cápsula incluye esta galería para combatir el reflejo común de "primero el gráfico, después el texto si sobra": en buenas visualizaciones, el texto no es un anexo sino una capa de información del mismo rango que las barras o las líneas.







Fuentes: mejor sin serifas
En InfoVis, si no estás seguro, ve a lo seguro y usa fuentes sin serifas. La comparación tipográfica (Fig. 20.2) resume la regla en un solo vistazo: una "Aa" sin remates (a la izquierda, ✓ YES) frente a la misma "Aa" con remates en cada trazo (a la derecha, ≈ MAYBE). Las sans-serif son menos ornamentadas y se leen nítidas en pantalla incluso a tamaños chicos; las serif, con esos remates en cada extremo, ensucian la lectura en cuerpos pequeños y compiten visualmente con las marcas de datos. Familias sans-serif gratuitas y solventes hay hartas — Roboto, Lato, Open Sans, Source Sans Pro, Noto Sans, Inter, Archivo — y casi nunca te vas a equivocar eligiendo una de esas. Las serif (Roboto Serif, Georgia, Garamond) rinden bien en libros impresos a alta resolución y pueden funcionar para títulos cuando se busca un toque editorial, pero requieren criterio tipográfico: si no sabes bien cuándo sus remates suman al texto, mejor déjalas para quien sí lo sabe.

Ordenar por valor
🔡 El orden alfabético no es «el» orden: es un descuido. Vas a ver el mismo ranking de exportadores de armas dos veces — primero como lo deja la herramienta, después ordenado por valor. Una lista de países es un dato nominal: no tiene un orden propio, así que «alfabético» no es más correcto que cualquier otro — es sólo el que la herramienta eligió por ti. Y si igual hay que elegir uno, elige el que cuenta la historia.
Después de borrar lo superfluo y de resaltar lo importante, queda un tercer ajuste que mejora el mensaje sin gastar una gota de tinta extra: el orden en que se disponen las categorías. No cambia ni un dato; sólo decide en qué fila va cada uno. Y, bien usado, convierte el gráfico en una respuesta en lugar de una búsqueda.
Considera un gráfico de lollipop que muestra la cantidad de armas vendidas por varios países en 2017. Por defecto (Fig. 20.3), los países aparecen en orden alfabético, lo que mezcla magnitudes grandes y pequeñas en cualquier posición y dificulta las comparaciones rápidas: los que más venden, como Estados Unidos y Rusia, saltan a la vista, pero comparar al resto exige un esfuerzo real del lector.

Al reordenar el gráfico según los valores de venta (Fig. 20.4), la visualización se vuelve mucho más informativa: ahora es inmediato ver que Francia es el tercer mayor exportador, seguido por Alemania, Israel y el Reino Unido. Las barras ordenadas forman una escalera descendente — una forma que el ojo lee de un vistazo. El ranking, que antes había que reconstruir número a número, pasó a ser preatentivo: la misma lectura sin esfuerzo que acabamos de ver con el color y la negrita.

¿Cuándo conviene NO reordenar? Sólo cuando la variable es ordinal — los meses del año, los días de la semana, las tallas S/M/L —: ahí el orden es parte del significado del dato y hay que respetarlo. Y ese es justamente el criterio para decidir. Pregúntate qué tipo de dato tienes en el eje: si es ordinal, el orden ya viene dado; si no lo es —y la mayoría de las variables categóricas nominales no lo son—, ningún orden es «el correcto», ni siquiera el alfabético. Puestos a elegir uno, el que comunica gana: ordena por valor.
Recuerda: vale para la explicativa
Recuerda que en una visualización de datos exploratoria, a diferencia de la explicativa, las estrategias de diseño para resaltar puntos específicos no son tan necesarias. El objetivo es permitir que cada usuario explore los datos de manera independiente y construya su propia interpretación sin guías predefinidas. En todos casos, sin embargo, es esencial proporcionar contexto adecuado para que los usuarios comprendan el propósito de su exploración y lo que están analizando. La flexibilidad en la exploración de datos permite descubrir insights y patrones por sí mismos, siempre y cuando se ofrezca suficiente contexto para facilitar su comprensión.
Cómo evaluar una InfoVis: absoluta/comparativa, formativa/sumativa, cuali/cuanti

¿Creen que su gráfico es bueno porque a ustedes les gusta? Monumento al ego. Evalúen. Absoluta o Comparativa. Formativa o Sumativa. Cualitativa o Cuantitativa.
Esta cápsula presenta los marcos conceptuales para pensar la evaluación de una InfoVis. Las técnicas concretas — think aloud, heurísticas, cuestionarios y pruebas cronometradas — se detallan en la cápsula siguiente (Cápsula 21).
Evaluación Absoluta y Comparativa
La evaluación de visualizaciones de datos puede abordarse desde dos enfoques diferentes: la evaluación absoluta y la evaluación comparativa.
Evaluación Absoluta
La evaluación absoluta se centra en determinar si una visualización de datos específica es efectiva y adecuada por sí misma. El esquema (Fig. 21.1) sintetiza el procedimiento: se pasa una sola infovis por un colador de criterios independientes — claridad, precisión, usabilidad, accesibilidad, interacción y satisfacción del usuario — sin necesidad de un referente comparativo. A través de este tipo de evaluación, se pueden identificar oportunidades de mejora y realizar ajustes necesarios para optimizar la visualización.

Evaluación Comparativa
Por otro lado, la evaluación comparativa implica analizar y comparar dos o más visualizaciones de datos para detectar diferencias significativas en su desempeño y eficacia. Este tipo de evaluación puede ser de dos tipos:
- Comparación Longitudinal: este enfoque se utiliza para evaluar distintas versiones de la misma visualización a lo largo del tiempo (Fig. 21.2). Permite identificar mejoras o retrocesos en la efectividad de la visualización tras la implementación de cambios. La comparación longitudinal es útil para medir el impacto de las modificaciones realizadas y para asegurar que las actualizaciones en el diseño realmente mejoren la experiencia del usuario.
- Comparación Transversal: en este caso, se comparan diferentes visualizaciones de datos que abordan el mismo tema o conjunto de datos (Fig. 21.3). Esta evaluación busca identificar cuál de las visualizaciones es más efectiva para comunicar la información, facilitando la selección de la mejor opción. La comparación transversal puede revelar qué estilos, formatos o enfoques son más atractivos o comprensibles para los usuarios.


Los dos enfoques son complementarios: la absoluta dice si una infovis funciona; la comparativa, cuál de varias alternativas funciona mejor.
Evaluación Formativa y Sumativa
La evaluación de visualizaciones también puede abordarse desde enfoques formativos y sumativos. La línea de tiempo (Fig. 21.4) sitúa ambos enfoques en el ciclo de vida del proyecto: la formativa ocurre durante el desarrollo, en puntos repetidos, mientras que la sumativa se aplica al final, una vez entregado el producto. Cada uno de estos enfoques — sin que uno excluya al otro — cumple un rol específico en el proceso de desarrollo, asegurando que la infovis sea efectiva y cumpla con los objetivos establecidos.

Evaluación Formativa
La evaluación formativa se lleva a cabo durante la fase de desarrollo de la visualización. Su objetivo principal es identificar fallos, debilidades o áreas de mejora en etapas tempranas del proceso, antes de que se complete la versión final. A través de la retroalimentación continua de usuarios y expertos, se pueden realizar ajustes y modificaciones en tiempo real, asegurando que la visualización evolucione de manera efectiva. Este enfoque permite abordar problemas antes de que se conviertan en obstáculos significativos, mejorando así la calidad del producto final y alineándolo más estrechamente con las necesidades de los usuarios.
Evaluación Sumativa
Por otro lado, la evaluación sumativa se realiza al final de la fase de desarrollo, una vez que se ha entregado la solución final. Su propósito es evaluar si la visualización cumple con los requisitos y expectativas establecidos al inicio del proyecto. Esta evaluación se centra en medir la efectividad de la infovis en términos de usabilidad, claridad y capacidad para comunicar la información de manera efectiva. Al realizar una evaluación sumativa, se pueden identificar fortalezas y debilidades finales, proporcionando una visión global del impacto de la visualización en el público objetivo. Los resultados de esta evaluación pueden influir en futuras iteraciones o proyectos relacionados.
La evaluación formativa garantiza una evolución continua y mejora del diseño, mientras que la sumativa proporciona una validación crítica del producto final y su alineación con las metas originales.
Evaluación Cualitativa y Cuantitativa
La distinción entre cualitativo y cuantitativo es transversal a las dos anteriores y describe qué clase de evidencia se recoge sobre la InfoVis.
- Evaluación Cualitativa — busca comprender experiencias, percepciones y comportamientos de los usuarios al interactuar con la visualización. El repertorio típico (Fig. 21.5) reúne las cuatro técnicas centrales: entrevistas uno a uno, grupos focales, observación directa y think aloud. Su fuerza está en captar matices sobre cómo y por qué los usuarios interactúan de cierta manera — muestras pequeñas, evidencia profunda.
- Evaluación Cuantitativa — recoge datos numéricos que se analizan estadísticamente. Las métricas clásicas (Fig. 21.6) son el tiempo de ejecución, la tasa de errores, las puntuaciones en escalas Likert y el tamaño de la muestra. Su fuerza está en permitir comparaciones y generalizaciones a partir de muestras más amplias — muestras grandes, evidencia agregada.


Los dos enfoques no son excluyentes: lo más común es un protocolo mixto que combina las dos clases de evidencia. La parte cualitativa te dice qué pasa, la cuantitativa te dice cuánto.
Ejemplo integrador: gestos de zoom en pantalla táctil
Para ver cómo los tres ejes (absoluto/comparativo, formativo/sumativo, cuali/cuanti) se cruzan en un estudio real, sirve un ejemplo del 2015. Se diseñaron dos gestos nuevos para hacer zoom en mapas y documentos sobre pantalla táctil — Tap&Tap para smartphones (controlable con una sola mano) y Two-Finger-Tap para tablets — como alternativas al clásico "pellizcar". La pregunta era simple: ¿son más rápidos y mejor percibidos que el gesto tradicional?
El estudio involucró a 18 usuarios de entre 22 y 42 años, todos usuarios habituales de pantallas táctiles. La mitad usaba el smartphone con una sola mano de manera regular; hartos necesitaban usar mapas con una mano (lo que ya por sí solo justifica el problema). El protocolo combinó dos técnicas complementarias:
- Cuestionario psicométrico con escala Likert de 6 puntos, aplicado al final de la sesión, para evaluar cada gesto en dimensiones como utilidad, intuitividad, claridad. Las preguntas se replicaron para los tres gestos (Tap&Tap, Two-Finger-Tap, pellizcar) para poder comparar. → evaluación comparativa + cuantitativa.
- Prueba de usuario cronometrada con 20 tareas concretas de zoom — del mapamundi hasta puntos específicos como Cerdeña, París, Madrid, el Reino Unido. El software registraba el tiempo automáticamente. → evaluación sumativa + cuantitativa.
Los resultados cuantitativos fueron contundentes: Two-Finger-Tap ahorró un 30% del tiempo respecto al pellizco tradicional en tablets, y Tap&Tap ahorró un 14% en smartphones. Combinado con la evaluación subjetiva del cuestionario, el conjunto dio evidencia robusta de que los nuevos gestos mejoraban la experiencia.
Es un ejemplo concreto de cómo articular dos métodos complementarios: el cuestionario cuenta cómo se sintió la interacción, la prueba cronometrada cuenta cómo funcionó objetivamente. Ningún método solo habría dado la misma confianza.
Think aloud, heurísticas de Zuk-Carpendale y checklist del curso

¿Cómo se evalúa en concreto? Usen el 'Think Aloud': pongan a 4 usuarios a usar su sistema y pidan que hablen en voz alta. Sus confusiones son los errores de ustedes.
Esta cápsula es el brazo práctico de la anterior: aquella dio los frameworks conceptuales (absoluta/comparativa, formativa/sumativa, cuali/cuanti); acá presentamos los métodos concretos para ejecutar una evaluación en un proyecto real: think aloud, heurísticas como soporte, cuestionarios psicométricos y pruebas de usuario cronometradas.
Think Aloud con heurísticas como soporte
El think aloud es el método cualitativo central: se observa a un grupo pequeño de usuarios (típicamente 4 a 5) mientras interactúan con la infovis, y se les pide verbalizar en voz alta lo que están pensando mientras la usan. Las pausas, las confusiones, las preguntas que surgen son la materia prima del análisis. El esquema (Fig. 22.1) recorre el método de punta a punta — de la sesión a la salida.

- Interpretación: los comportamientos y comentarios de los usuarios se analizan en relación con heurísticas de diseño conocidas — principios validados por la comunidad InfoVis (ver lista más abajo).
- Salida: una lista de problemas de usabilidad, definidos como discrepancias entre el comportamiento del usuario y las heurísticas.
- Uso típico: método formativo — los problemas detectados se transforman en oportunidades de mejora para la siguiente iteración.
📌 Importante. Este es el método que se espera utilicen en los proyectos del curso: pongan a 4 usuarios reales (no compañeros del equipo) frente al prototipo, pídanles que verbalicen, registren los puntos donde se traban. Es barato, rápido y revela más de lo que cualquier auto-revisión podría.
Heurísticas de Zuk & Carpendale — checklist transversal del curso
Las heurísticas de Zuk y Carpendale son 13 principios que condensan buena parte de lo que el curso vio, cápsula por cápsula. Sirven como soporte al think aloud y, sobre todo, como una checklist de auto-revisión rápida antes de mostrarle la InfoVis a alguien. Recórrelas una por una — donde el principio ya apareció, la imagen te devuelve a la cápsula que lo trató a fondo.
📊 1. Variables visuales aptas para comparar. Las diferencias de longitud, tamaño o posición tienen que ser bien visibles — y no todas las señales se comparan con la misma precisión.
El ranking que mide esa precisión: Fig. 22.2
🌈 2. El color no tiene orden. No esperes que el lector lea una secuencia en los tonos: el color es categórico, no ordinal — un arcoíris no dice «de menos a más».
Las tres dimensiones del color, y cuál sirve para qué: Fig. 22.3
🎨 3. El color depende del tamaño. Un mismo color se percibe distinto en un punto diminuto que en un bloque grande.
En elementos chicos, sube la saturación o el contraste para que el color siga siendo legible.
🌗 4. El contraste local engaña. Un color — o un gris — se percibe distinto según lo que tenga al lado: el vecindario altera lo que ves.
Las dos celdas parecen bien distintas (Fig. 22.4)… hasta que les borras el contexto de alrededor y se revela que son idénticas (Fig. 22.5).
👁️ 5. Diseña para el daltonismo. Cerca del 8 % de los hombres no distingue ciertos pares de colores; el rojo-verde es el más traicionero.
Un mapa de la prevalencia del daltonismo en el mundo (Fig. 22.6) y ese mismo mapa como lo ve un ojo daltónico (Fig. 22.7) — ilegible justo para quien trata.
⚡ 6. Usa los atributos preatentivos con criterio. El color, el tamaño y la orientación los detecta el ojo en milisegundos, sin esfuerzo consciente.
Cuenta los «3» en gris uniforme (Fig. 22.8) y después con los «3» en color (Fig. 22.9): la segunda respuesta salta sola.
📏 7. Lo cuantitativo se lee en posición y tamaño. Para que el lector estime cantidades, codifica la magnitud en señales que se miden bien — posición y longitud antes que color o área.
El catálogo de señales visuales: Fig. 22.10
🧊 8. Preserva la dimensionalidad del dato. Casi nunca uses 3D — y menos si los datos son 2D: la perspectiva deforma los tamaños y tapa valores.
El 3D que vuelve la lectura una adivinanza: Fig. 22.11
🗜️ 9. Más datos en menos espacio. Aprovecha cada pixel: un gráfico denso pero ordenado comunica más que diez gráficos sueltos.
Ideas por unidad de tinta y de espacio — la versión moderna del diagrama de Tufte: Fig. 22.12
✂️ 10. Borra lo superfluo. Cada gota de tinta que no codifica un dato compite con la que sí: si un elemento no aporta, fuera.
El antes y el después lado a lado — del gráfico recargado al limpio: Fig. 22.13
🧩 11. Aprovecha las leyes de la Gestalt. Proximidad, similitud, continuidad: el ojo agrupa por su cuenta — diseña para que agrupe lo correcto.
Repaso de los principios: Leyes de la Gestalt.
🔭 12. Ofrece varios niveles de detalle. Primero la vista general, después el zoom y el filtro, y el dato puntual sólo cuando se pide.
Es el mantra de Shneiderman, que se trata a fondo más adelante, en la cápsula de interactividad.
✍️ 13. Integra el texto. Títulos, etiquetas y anotaciones son parte del gráfico, no un adorno: bien puestos, guían la lectura.
El mismo scatter sin una palabra de contexto (Fig. 22.14) y después anotado, vuelto una historia (Fig. 22.15).
Que casi ninguna de estas heurísticas sea nueva no es casualidad: el curso entero está construido sobre estos principios. La lista funciona como inventario de cierre — antes de evaluar formalmente con usuarios, recórrela y verifica que el diseño no rompa ninguna de forma obvia.
Cuestionarios Psicométricos
Mientras el think aloud recoge evidencia cualitativa profunda con pocos usuarios, los cuestionarios psicométricos recogen evidencia cuantitativa con muestras más grandes (típicamente ~24 usuarios). Se administran después de una interacción — incluso breve, como una mirada de 10 segundos — y miden dimensiones percibidas de la InfoVis.
Estos cuestionarios pueden ser:
- Evaluación absoluta: analizar la calidad de una única InfoVis, ver si los usuarios la perciben positivamente o no. Ejemplo: un test binomial sobre respuestas Likert.
- Evaluación comparativa: comparar varias versiones de la misma InfoVis, o distintos grupos de usuarios. Ejemplo: un t-test (o equivalente no paramétrico) para detectar si las diferencias entre versiones son estadísticamente significativas.
Un cuestionario se considera validado si fue ampliamente adoptado por la comunidad académica o profesional, o si demostró confiabilidad medida con métricas estandarizadas (alfa de Cronbach, etc.). Un ejemplo validado específico para InfoVis es el de Locoro et al. (2017), que mide cinco dimensiones perceptivas: utilidad, claridad, capacidad informativa, belleza y valor general.
Pruebas de Usuario cronometradas
En una prueba de usuario los diseñadores observan a un grupo (~12 personas) realizando tareas concretas sobre la InfoVis, y registran datos objetivos:
- Planificación: las tareas se diseñan de antemano según los objetivos específicos de la InfoVis (informar, demostrar, capacitar). Tienen que ser no triviales — el usuario debe usar la infovis de verdad.
- Medidas cuantitativas: tasa de error, tiempo de ejecución, tasa de éxito. Datos objetivos del rendimiento.
- Comparación: las pruebas de usuario son típicamente comparativas — se compara una versión con otra, o contra un valor óptimo de referencia.
- Uso típico: método sumativo — se aplica con un diseño avanzado o terminado, para confirmar si cumple los objetivos.
Cómo combinar los métodos
Los tres métodos no compiten — se complementan. Una secuencia típica en un proyecto serio:
- Auto-revisión con la checklist de Zuk-Carpendale (gratis, 10 minutos). Filtra los errores obvios.
- Think aloud con 4-5 usuarios (formativo). Revela los puntos donde el usuario se traba. Salida: lista de problemas a corregir.
- Iterar el diseño corrigiendo lo encontrado en el paso 2.
- Cuestionario psicométrico con 20-25 usuarios sobre la versión refinada. Mide percepción cuantitativa.
- Prueba de usuario cronometrada con 10-15 usuarios (sumativa). Confirma rendimiento objetivo antes de cerrar el proyecto.
El ejemplo de los gestos Tap&Tap de la cápsula anterior muestra este patrón en acción: cuestionario psicométrico + prueba cronometrada, los dos juntos dieron evidencia robusta de que el diseño funcionaba.
T1. Plotly.js: del CSV al gráfico estático en el navegador
Del Excel al gráfico en el navegador, paso a paso. Sin interacción todavía.
Excel hace gráficos. El navegador también — y mejor. Vamos del CSV al gráfico estático en menos líneas de código que las que tarda Excel en abrir el archivo.
¿Qué es Plotly.js?
Una librería open-source para gráficos interactivos basados en D3.js + WebGL. En esta cápsula la usamos solo para hacer gráficos estáticos: nada de eventos al hacer clic, nada de sonido. Eso vendrá después.
Por qué empezar estáticos. Una buena InfoVis tiene que comunicar antes de tocarla. Si necesita interacción para entenderse, la composición está mal. Construimos primero la versión "publicable" — la que funcionaría impresa.
Paso 1 — Diseñar los datos en Excel / Google Sheets
Empezamos en Excel (o Google Sheets) porque es el lugar más cómodo para ver y validar los datos antes de tocar código (Fig. 23.1). Una columna por variable, una fila por observación.

En el ejemplo: month, processed, received.
Paso 2 — Exportar a CSV
File → Download → Comma-separated values (.csv). El archivo resultante es
texto plano, una fila por línea, columnas separadas por coma:
month,processed,received
Ene,160,160
Feb,184,184
Mar,237,241
Abr,148,149
May,181,180
Jun,150,161
Jul,123,132
Ago,156,202
Sep,126,160
Oct,104,139
Nov,124,149
Dic,140,177
Paso 3 — Convertir CSV → JSON
Necesitamos pasar de CSV a un array de objetos JSON: el formato que JavaScript entiende nativamente. La salida que buscamos es:
[
{ "month": "Ene", "processed": 160, "received": 160 },
{ "month": "Feb", "processed": 184, "received": 184 },
{ "month": "Mar", "processed": 237, "received": 241 },
...
]
La conversión en pocas líneas de JavaScript
No hace falta depender de un sitio externo. Plain JS, una sola pasada por las filas:
function csvToJson(csv) {
const [header, ...rows] = csv.trim().split('\n').map(r => r.split(','));
return rows.map(r => Object.fromEntries(
header.map((h, i) => {
const v = r[i].trim();
const n = Number(v);
return [h.trim(), Number.isFinite(n) && v !== '' ? n : v];
})
));
}
const datos = csvToJson(`month,processed,received
Ene,160,160
Feb,184,184
Mar,237,241`);
// → [{ month:"Ene", processed:160, received:160 }, ...]
Herramienta del curso — pegar y copiar
Para usarla cuando armas el dataset del proyecto, el curso distribuye una mini-página local con esa lógica adentro: pegas el CSV, te devuelve el JSON listo para copiar.
→ Abrir la herramienta CSV → JSON
Por qué local. Los datos no salen de tu navegador. Útil cuando trabajas con datasets sensibles (registros, cifras internas, …).
Paso 4 — Pegarlo como variable JS
Copiamos ese JSON en el HTML, dentro de un <script>, asignándolo a una
variable:
let datos = [
{ month: "Ene", processed: 160, received: 160 },
{ month: "Feb", processed: 184, received: 184 },
// …doce filas en total
];
A esta altura los datos están en el navegador. Falta darles a Plotly el formato que él espera.
Paso 5 — Plotly necesita arrays paralelos
Plotly no entiende un array de objetos. Necesita arrays separados, uno por columna. Es decir, en vez de:
[ {month:"Ene", y:160}, {month:"Feb", y:184}, … ]
Plotly quiere:
month = ["Ene", "Feb", …]
y = [160, 184, …]
Para extraer cada columna usamos el método .map() de los arrays. .map()
recorre el array y devuelve uno nuevo aplicando una función a cada elemento.
Acá la función simplemente toma una propiedad del objeto:
let month = datos.map(item => item.month); // ["Ene","Feb","Mar",…]
let processed = datos.map(item => item.processed); // [160, 184, 237, …]
let received = datos.map(item => item.received); // [160, 184, 241, …]
.map()en una línea: toma este array y dame uno nuevo, aplicando esta función a cada elemento. Es el método con el que vamos a reformatear casi todo en este curso.
Paso 6 — Crear el gráfico
Plotly recibe traces (los datos) y un layout (título, ejes, …):
const trace1 = { x: month, y: processed, type: 'bar', name: 'Procesados' };
const trace2 = { x: month, y: received, type: 'bar', name: 'Recibidos' };
const layout = { title: 'Volumen de tickets por mes' };
Plotly.newPlot('myDiv', [trace1, trace2], layout);
'myDiv' es el id del <div> donde se dibujará el gráfico. El resultado:
📚 Didáctica · solo muestra el mecanismo, no es lo que esperamos en el proyecto
Pasar de "se ve" a "se entiende"
El demo anterior es funcional pero mudo. No dice qué está pasando. Una buena InfoVis usa anotaciones, énfasis y texto para llevar al lector al mensaje:
🎯 Esperada · este es el nivel del proyecto
Mismos datos, otra cosa. Llegamos ahí con líneas + marcadores + texto +
anotaciones, y staticPlot: true para apagar incluso el zoom y el modebar:
Plotly.newPlot('myDiv', [trace1, trace2], layout, { staticPlot: true });
Otro ejemplo, otra historia — la brecha salarial en EE.UU.
Hasta acá vimos los pasos sobre un mismo dataset. Ahora miramos un caso diferente — otra InfoVis completa, otros datos, otro mensaje — pero del mismo nivel narrativo. Salario semanal mediano por estado, hombres en X, mujeres en Y:
🎯 Esperada · este es el nivel del proyecto
Ingredientes que no estaban en el ejemplo anterior:
shapes— la línea diagonal "salario igual" (y = x)annotationsflotantes — "WOMEN PAID MORE", "MEN PAID MORE", "Equal pay"- Anotaciones específicas con flecha sobre dos estados (Wyoming, Vermont) que cuentan la historia: "menos equitativo" / "más equitativo"
Sin esos elementos sería un scatter cualquiera. Con ellos, se entiende sin explicación. Eso es nivel de proyecto.
Más versiones esperadas — proyectos del curso (estáticos)
Estas son visualizaciones hechas por estudiantes en años anteriores, acá mostradas en su versión estática (sin interacción ni sonido). Son nivel de proyecto: tienen contexto, jerarquía, paleta cuidada y un mensaje claro. La interacción y la sonificación se añaden después (T3, T4) cuando aportan, no porque sí.
Autos más rápidos del mundo
Comparativa visual de los autos más veloces — silueta vectorial, ejes limpios, jerarquía tipográfica.
🎯 Proyecto del curso (Grupo 29, 2024-II) · versión estática.
100m planos en las olimpiadas
Evolución temporal de los tiempos ganadores — un scatter narrado con anotaciones sobre los hitos importantes.
🎯 Proyecto del curso (Grupo 13, 2024-II) · versión estática.
Viento V Región (Chile)
Velocidad del viento durante 2024 en la Quinta Región — serie temporal con dos eventos extremos anotados directamente sobre la línea (el sistema frontal del 13 de junio y los temporales del 2 de agosto).
🎯 Proyecto del curso (Grupo 14, 2024-II) · versión estática.
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaPor favor, contraten dos personas — versión narrativa🎯 EsperadaBrecha salarial en EE.UU. — scatter con anotaciones🎯 EsperadaAutos más rápidos — versión estática (proyecto estudiante)🎯 Esperada100m olímpicos — versión estática (proyecto estudiante)🎯 EsperadaViento V Región — versión estática (proyecto estudiante)
T2. Plotly Geo: scattergeo, choropleth y SVG de contexto con Inkscape
Datos geoespaciales: scattergeo, choropleth y un mapa SVG de contexto
Los datos no viven solo en filas y columnas: tienen latitud, longitud, fronteras. Mapearlos no es magia — son tres líneas de Plotly y un SVG de contexto cuando el detalle lo pide.
Datos con dimensión geográfica
Cuando los datos tienen latitud/longitud o pertenecen a regiones (países, comunas, …), Plotly ofrece dos primitivas para mapearlos:
scattergeo— puntos sobre el mapa (coordenadas exactas)choropleth— colorea regiones completas según un valor
A menudo se combinan: un choropleth de un solo color como fondo del
país, con un scattergeo de eventos encima.
Paso 1 — Los datos de los terremotos
Trabajamos con un archivo de terremotos chilenos desde el año 2000. Cada fila tiene fecha, nombre, latitud, longitud, magnitud, regiones afectadas, si hubo tsunami y número de muertos:
[
{ "Fecha": "24-jul-2001", "Nombre": "Tarapacá", "Lat": -19, "Lon": -70, "Magnitud": 6.5, "Tzunami": false, "Muertos": 1 },
{ "Fecha": "18-abr-2002", "Nombre": "Copiapó", "Lat": -27.5, "Lon": -70.6, "Magnitud": 6.8, "Tzunami": false, "Muertos": 0 },
{ "Fecha": "14-nov-2007", "Nombre": "Tocopilla", "Lat": -22.3, "Lon": -70.0, "Magnitud": 7.7, "Tzunami": false, "Muertos": 2 },
...
]
Paso 2 — Versión didáctica: solo el mecanismo
Dos traces y Plotly.newPlot(). Sin contexto ni narrativa:
const fondoChile = {
type: 'choropleth',
locations: ['CHL'],
z: [0], // un solo valor, color uniforme
colorscale: [[0,'#eee'], [1,'#eee']],
showscale: false,
hoverinfo: 'skip'
};
const sismos = {
type: 'scattergeo',
lon: terremotos.map(t => t.Lon),
lat: terremotos.map(t => t.Lat),
mode: 'markers',
marker: {
size: terremotos.map(t => t.Magnitud * 3),
color: terremotos.map(t => t.Magnitud),
colorscale: 'YlOrRd', cmin: 5, cmax: 9
}
};
Plotly.newPlot('map', [fondoChile, sismos], {
geo: {
scope: 'south america',
showland: true, landcolor: '#fafafa',
lonaxis: { range: [-78, -65] },
lataxis: { range: [-58, -17] }
}
});
📚 Didáctica · solo muestra el mecanismo, no es lo que esperamos en el proyecto
Truco: el
choroplethconz=[0]y un único color se usa solo como fondo del país. No codifica datos — sirve para que la silueta de Chile sea visible.
Paso 3 — Mapa de contexto con Inkscape
A veces el mapa built-in no alcanza. Quieres líneas de fallas, nombres de ciudades, una tipografía propia, etiquetas directas sobre los puntos importantes. La solución del curso: dibujar un SVG aparte con Inkscape y superponerlo sobre el mapa de Plotly (Fig. 24.1).
Inkscape es gratuito y multiplataforma. Permite:
- editar SVG existentes
- añadir IDs a elementos para manipularlos desde JS
- crear elementos visuales personalizados que Plotly no ofrece — etiquetas con flechas, leyendas, jerarquía tipográfica
Paso 4 — Superponer el SVG al mapa Plotly
<div id="title">
<h1>Terremotos de Chile desde el 2000</h1>
</div>
<div id="myMap"></div>
<img id="context" src="map.svg" />
#myMap { position: absolute; width: 200px; height: 800px; left: 30px; top: 0; }
#context { position: absolute; pointer-events: none; top: 85px; left: 83px; }
pointer-events: none deja que el mapa de Plotly siga "viendo" el mouse
debajo de la imagen SVG.
Versión esperada — con SVG, etiquetas y jerarquía
Mismos datos, pero ahora la historia visual está completa: título grande, los tres terremotos más grandes etiquetados directamente con su nombre, año y rango ("El más fuerte del siglo"), y un fondo coherente:
🎯 Esperada · este es el nivel del proyecto
Información siempre visible. La información clave (nombres, años, magnitudes de los terremotos importantes) está rotulada directamente sobre el SVG. El lector entiende la imagen sin tener que tocar nada.
Más proyectos del curso (versiones estáticas)
Estos son demos hechos por estudiantes en años anteriores, mostrados acá en su versión estática (sin interacción ni sonido). Son nivel de proyecto: mapas con composición narrativa, paleta cuidada y un mensaje claro.
Montañas rusas más rápidas
scattergeo con burbujas proporcionales a la velocidad. Top 10 a la
izquierda, ficha de la #1 (Formula Rossa, Abu Dhabi, 240 km/h) a la
derecha, y una flecha diagonal que la señala directamente sobre el mapa.
🎯 Proyecto del curso (Grupo 4, 2024-II).
Consumo eléctrico por región de Chile
choropleth que carga un GeoJSON personalizado de las regiones chilenas
(no el mapa built-in) y colorea cada una según su consumo per cápita en
2020.
🎯 Proyecto del curso (Grupo 6, 2024-II).
Migración de gaviota
scattergeo con líneas que conectan posiciones GPS de una gaviota a lo
largo de un año. El color de cada tramo cambia según la estación
(verano/otoño/invierno/primavera) y los hitos del viaje están etiquetados
directamente sobre el mapa.
🎯 Proyecto del curso (Grupo 21, 2024-II).
Gasto militar mundial (2018)
choropleth con locationmode: 'country names' (sin GeoJSON propio,
Plotly trae los contornos de los países). Escala de color YlOrRd, anotación
con flecha sobre Arabia Saudí.
🎯 Proyecto del curso (Grupo 22, 2024-II).
Países anfitriones de los Mundiales de Fútbol
Otro choropleth con country names, paleta categórica (0-3 mundiales),
proyección Robinson, leyenda externa en HTML, y una anotación con flecha
sobre México (próximo país en ser sede 3 veces, en 2026).
🎯 Proyecto del curso (Grupo 17, 2024-II).
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaMapa de terremotos con SVG de contexto🎯 EsperadaMontañas rusas más rápidas — versión estática (proyecto estudiante)🎯 EsperadaConsumo eléctrico por región de Chile — versión estática (proyecto estudiante)🎯 EsperadaMigración de gaviota — versión estática (proyecto estudiante)🎯 EsperadaGasto militar mundial 2018 — versión estática (proyecto estudiante)🎯 EsperadaPaíses anfitriones de los Mundiales — versión estática (proyecto estudiante)
Interactividad: overview, zoom & filter, details on demand
El mantra de la interacción visual: 'Overview first, zoom and filter, then details-on-demand'. Muestra el bosque antes de enfocarte en las hojas.
Cuando los datos son grandes o complejos, las visualizaciones estáticas pueden resultar insuficientes para proporcionar una comprensión completa y profunda. Es aquí donde la interactividad desempeña un papel crucial: convierte la visualización en una herramienta adaptativa — el usuario ya no sólo observa los datos, los explora de manera dinámica, ajustando la representación a sus propias preguntas en tiempo real.
En esta cápsula nos centramos exclusivamente en la interacción visual y en cómo organizarla siguiendo un principio guía claro: el mantra de Shneiderman. La extensión auditiva de los datos —la sonificación— se trata por separado, en su propia cápsula.
Interacción
El mantra de Shneiderman
Las interacciones más comunes se organizan siguiendo el mantra de la visualización interactiva de Shneiderman: "Primero, una vista general; luego, ampliar y filtrar; después, detalles bajo demanda" (Overview first, zoom and filter, then details-on-demand).
Este mantra propone una secuencia natural de exploración: empezamos viendo el bosque entero, luego acercamos el lente a una zona, y finalmente examinamos un árbol en concreto. Cada fase apoya a la siguiente y evita que el usuario se pierda en detalles antes de tener un mapa mental del conjunto.
Overview First: Vista General
La primera fase entrega una vista panorámica del conjunto: el usuario capta la estructura y los patrones generales —la distribución, las relaciones más amplias— antes de que ningún detalle lo distraiga. Por ejemplo, un gráfico de ventas globales muestra primero el resumen de todas las regiones; recién después se baja al detalle.
Zoom and Filter: Ampliar y Filtrar
🔍 Visto el bosque, te acercas a un árbol. Es la segunda fase del mantra — y los demos que siguen te la dejan probar con la mano: zoom y scroll, filtrado dinámico y slider temporal. Lo que tienen en común: cada uno recorta lo que se ve, pero ninguno te hace perder de vista dónde estás dentro del conjunto.
Zoom y Scroll (Fig. 25.1): el zoom es esencial para explorar datos a distintos niveles de detalle. Por ejemplo, en un mapa interactivo, se puede hacer zoom desde una vista de continente hasta ver calles. El scroll (o pan) complementa esta interacción, permitiendo desplazarse por diferentes áreas de la visualización. Estas interacciones son clave cuando se trata de grandes volúmenes de datos o visualizaciones que ocupan más espacio que el visible en pantalla.
Filtrado Dinámico (Fig. 25.2): el filtrado permite ajustar lo que se muestra, enfocando aspectos específicos. Por ejemplo, en un gráfico de barras sobre ventas por región, el filtrado dinámico podría permitir seleccionar productos o periodos de tiempo específicos, reduciendo el "ruido visual" y centrando la atención en datos relevantes.
Ajuste Temporal con Sliders (Fig. 25.3): para los datos que varían con el tiempo, un slider le devuelve al lector el control del eje temporal. El caso más directo es un slider que recorre los años: el usuario lo arrastra y la visualización salta al año elegido, mostrando una época a la vez en lugar de apilar todas las épocas en un gráfico ilegible. Un slider de rango va un paso más allá: con sus dos extremos el lector acota una ventana de fechas y los datos se recortan a ese tramo — su forma más simple, sobre una sola serie, es el precio de Apple (Fig. 25.4). En ambos casos es el lector quien decide qué porción del tiempo mirar, sin sobrecargar la vista con todo a la vez.
Details-on-Demand: Detalles Bajo Demanda
🖱️ Ajustada la vista, pides el dato exacto. La fase final del mantra tiene una sola regla: la vista general se mantiene limpia y el detalle llega sólo cuando el usuario lo pide — con un tooltip al pasar el cursor, o seleccionando los elementos que quiere mirar de cerca.
Tooltip en Hover (Fig. 25.5): el hover es una interacción ligera pero poderosa. Al pasar el cursor sobre un elemento de la visualización aparece un tooltip con información adicional sin alterar la estructura general. Esto es especialmente útil en gráficos de dispersión o mapas (Fig. 25.6), donde un tooltip puede mostrar detalles como valores exactos o contexto adicional sobre un punto específico.
Selección de Elementos: permitir que los usuarios seleccionen elementos individuales o múltiples en una visualización añade personalización. Por ejemplo, en un gráfico de dispersión, el usuario puede usar una selección rectangular o de lazo para resaltar varios puntos a la vez y examinarlos más a fondo, mientras atenúa los otros elementos.
Otras Manipulaciones en Visualización de Información
🎛️ Dos palancas que no entran en el mantra — pero valen oro. Animación temporal y cambio de representación. Lo que las une: cada una le pasa al usuario una decisión que solía tomar el diseñador — qué momento ver y en qué codificación leerlo.
Animaciones Temporales (Fig. 25.7): las animaciones permiten observar cómo evolucionan los datos a lo largo del tiempo. Por ejemplo, una visualización de crecimiento poblacional al estilo Gapminder puede usar animaciones para mostrar los cambios por década, y el usuario puede pausar o ajustar la velocidad según su interés en ciertos periodos temporales. Otro patrón frecuente: un mapa del mundo donde la intensidad de cada zona evoluciona año a año (Fig. 25.8).
Cambio de Representación Visual (Fig. 25.9): los usuarios pueden alternar entre diferentes representaciones de los mismos datos —por ejemplo, entre porcentajes y valores absolutos, o entre barras y líneas— con un solo clic. Esta interacción permite descubrir nuevos patrones o insights que no serían evidentes en una única representación visual.
T3. Plotly interactivo: implementando el mantra de Shneiderman
Implementar el mantra Overview → Zoom & Filter → Details on Demand
Overview first, zoom & filter, details on demand. Las tres palabras de Shneiderman que separan un PDF estático de una herramienta exploratoria.
Del gráfico estático a la exploración
Hasta T2 todo era estático: el lector lee la imagen y pasa de página. En la cápsula 22 (Primero el Bosque, Después el Árbol) vimos el mantra de Shneiderman:
Overview first → Zoom & Filter → Details on Demand
Esta cápsula implementa cada paso del mantra con Plotly y muestra cómo los proyectos del curso lo aplican.
No hace falta tener los tres pasos. Algunos proyectos solo necesitan details on demand (el mapa de terremotos: ya ves todo, el hover añade detalle). Otros solo zoom & filter (una serie temporal larga donde el filtro por año da legibilidad). Otros los tres. Decidí qué hace falta según los datos, no por completar la lista.
Eventos en Plotly — la base técnica
Plotly emite eventos cada vez que el usuario interactúa con el gráfico. Suscribirse es una sola línea:
const div = document.getElementById('myDiv');
div.on('plotly_hover', e => { /* mouse encima de un punto */ });
div.on('plotly_unhover', e => { /* el mouse se va */ });
div.on('plotly_click', e => { /* clic en un punto */ });
div.on('plotly_selected', e => { /* selección con el lasso */ });
Cada evento recibe un objeto e donde e.points[0] apunta al dato bajo
el cursor: e.points[0].x, e.points[0].y, e.points[0].pointIndex.
Con esto resolvemos los tres pasos del mantra. Vamos en orden.
Paso 1 — Overview: la vista general
El primer paso del mantra es mostrar el bosque entero antes que cualquier árbol. Esto ya lo hicimos en T1 y T2: cada gráfico estático que produjimos es un overview.
- T1: brecha salarial (50 estados a la vez), tickets de soporte (12 meses), velocidades de auto, medallistas olímpicos, viento V Región
- T2: terremotos de Chile, electricidad por región, migración de gaviota, gasto militar mundial, mundiales de fútbol, montañas rusas
Antes de añadir cualquier interacción, asegurate que el overview ya se entiende solo. Si el gráfico estático no comunica nada, la interactividad no lo va a salvar.
Damos el overview por hecho a partir de acá y nos enfocamos en los dos pasos siguientes.
Paso 2 — Zoom & Filter
El segundo paso del mantra: cuando los datos son muchos, dejar al lector acotar la vista a la porción que le interesa.
Lo más simple: un <select> que filtra por categoría y vuelve a dibujar.
Plotly.react() es la versión eficiente de newPlot(): sustituye los datos
sin re-crear todo el gráfico.
document.getElementById('anio').addEventListener('change', e => {
const año = e.target.value;
const filtrados = (año === 'ALL')
? datos
: datos.filter(d => d.fecha.startsWith(año));
Plotly.react('myDiv', tracesDe(filtrados), layout);
});
Apple stock + filtro por año (menú) · sólo filtro
Tres años de cotización Apple en una sola línea. Un <select> con los años
permite acotar la vista. Sin hover panel — esta versión muestra el
filtro puro, no el detalle bajo el cursor:
function render(year) {
const { x, y } = filterByYear(year);
Plotly.react('myDiv', [buildTrace(x, y)], { hovermode: false });
}
yearSelect.addEventListener('change', e => render(e.target.value));
📚 Didáctica · sólo el filtro. Compará con la versión 4 más abajo, donde los tres pasos del mantra coexisten.
Apple stock + filtro por slider (rango continuo) · sólo filtro
Variante más expresiva: dos <input type=range> definen un rango de
índices. El usuario puede acotar a una ventana arbitraria, no a una
categoría fija. Útil para comparar dos ventanas temporales (ej. el bajón de
mayo 2016 vs. la recuperación de fin de año). Tampoco hay hover — sólo
filtro.
sliderMin.addEventListener('input', render);
sliderMax.addEventListener('input', render);
function render() {
const a = +sliderMin.value, b = +sliderMax.value;
const x = APPLE_DATES.slice(a, b + 1);
const y = APPLE_PRICES.slice(a, b + 1);
Plotly.react('myDiv', [buildTrace(x, y)], { hovermode: false });
}
📚 Didáctica · misma idea, control más fino, sin hover.
Cuándo el filtro sí importa
Los filtros de arriba son didácticos: la serie temporal de Apple ya se lee bien sin filtrar. Pero hay casos donde filtrar es lo que hace la visualización entendible:
- muchas categorías superpuestas — la brecha salarial: 50 estados a la vez tapan unos a otros, filtrar por región abre legibilidad
- rangos temporales largos con eventos puntuales — terremotos 2000–2024: filtrar por década permite contar una historia por período
- una variable temporal continua — un slider de año que barre un mapa década a década (lo veremos abajo en gasto militar mundial)
Antes de añadir un filtro preguntate: ¿el lector entiende mejor con esto, o solo es decoración interactiva? Si la respuesta es "decoración", probablemente sobra.
Paso 3 — Details on Demand
El tercer paso del mantra: una vez que el lector ya está mirando una zona, permitirle pedir el detalle de un dato individual sin saturar la interfaz inicial.
La técnica básica: hover (o clic) muestra un panel HTML con la información extra; al sacar el mouse el panel desaparece.
Graphicacy: cuando muestres detalles, muestra el número como elemento visual (una barra que crece, un punto en una escala, un bar chart secundario) — no como texto crudo. El curso de InfoVis es sobre traducir números a percepción: aplicalo también en los paneles de detalle.
Hover básico (sólo el mecanismo)
Un bar chart simple. Cuando el mouse pasa sobre una barra, un <div> debajo
se actualiza con el mes y el valor:
Plotly.newPlot('myDiv', [{ x: meses, y: valores, type: 'bar' }]);
document.getElementById('myDiv').on('plotly_hover', e => {
const p = e.points[0];
document.getElementById('info').innerHTML = `<b>${p.x}</b> → ${p.y} tickets`;
});
document.getElementById('myDiv').on('plotly_unhover', () => {
document.getElementById('info').innerHTML = '— pasa el mouse sobre una barra —';
});
📚 Didáctica · solo muestra el mecanismo, no es lo que esperamos en el proyecto.
Hover sobre línea temporal (Apple stock)
La misma técnica sobre una serie temporal larga. La clave: desactivar el
tooltip por defecto de Plotly (hoverinfo: 'none') y reemplazarlo con un
panel HTML controlado por nosotros, con hovermode: 'x' para que el cursor
"enganche" el dato vertical más cercano.
const trace = {
x: APPLE_DATES, y: APPLE_PRICES,
type: 'scatter', mode: 'lines',
hoverinfo: 'none' // apagamos el tooltip estándar
};
Plotly.newPlot('myDiv', [trace], { hovermode: 'x' });
myDiv.on('plotly_hover', e => {
const p = e.points[0];
info.innerHTML = `<b>${p.x}</b> → $${p.y.toFixed(2)}`;
});
📚 Didáctica · misma técnica, ahora sobre 504 días de cotización.
Hover con panel narrativo (brecha salarial)
Tomamos el scatter de la brecha salarial de T1 y le añadimos hover con un panel lateral que muestra el estado, el sueldo de mujeres y el sueldo de hombres bajo el cursor:
const trace = {
x: maleSalaries, y: femaleSalaries,
mode: 'markers',
hoverinfo: 'none', // ← apaga el tooltip estándar
marker: { size: 4, color: '#888' }
};
myDiv.on('plotly_hover', data => {
const i = data.points[0].pointIndex;
document.getElementById('state').textContent = states[i];
document.getElementById('woman').textContent = '$' + femaleSalaries[i];
document.getElementById('man').textContent = '$' + maleSalaries[i];
document.getElementById('details').style.display = 'block';
});
myDiv.on('plotly_unhover', () => {
document.getElementById('details').style.display = 'none';
});
🎯 Esperada · este es el nivel del proyecto. Pasa el mouse sobre los puntos.
Decisión: aquí no hay filtro. Con 50 estados, details on demand ya basta para responder la pregunta "¿cómo está mi estado?". Añadir filtro por región sería acumular interacción: la lectura no mejora. El mantra es guía, no checklist.
Mapa de terremotos interactivo
Tomamos el mapa estático de T2 y le añadimos hover. Sin audio todavía — eso es T4. Cuando el mouse entra a un terremoto:
- el panel lateral muestra nombre, regiones, magnitud, muertos
- aparece un ícono de tsunami si hubo
- se oculta el SVG de contexto (las etiquetas estáticas), porque ahora el panel da los detalles
myMap.on('plotly_hover', data => {
const t = terremotos[data.points[0].pointIndex];
document.getElementById('nombre').innerHTML = t.Nombre;
document.getElementById('regiones').innerHTML = t.Zonas;
document.getElementById('muertos').innerHTML = t.Muertos;
document.getElementById('magnitud').innerHTML = t.Magnitud;
if (t.Tzunami) document.getElementById('tzunami').style.display = 'block';
document.getElementById('details').style.opacity = 1;
document.getElementById('context').style.opacity = 0; // ocultamos las etiquetas
});
myMap.on('plotly_unhover', () => {
document.getElementById('details').style.opacity = 0;
document.getElementById('context').style.opacity = 1; // restauramos
});
🎯 Esperada · este es el nivel del proyecto. Pasa el mouse sobre cada terremoto.
Otra vez, sin filtro. Los terremotos son ~30 puntos sobre el mapa de Chile — ya se ven todos. Filtrar por década reduciría puntos que no estaban estorbando. Details on demand suficiente.
Combinar los pasos del mantra
A veces los tres pasos coexisten en un mismo viz. La regla: añadí cada paso solo si responde a una pregunta del lector que los anteriores no responden.
Ejemplo didáctico — Apple stock con los tres pasos
La misma serie temporal de antes, pero ahora:
- Overview — la línea completa al cargar
- Zoom & Filter — el
<select>reduce a un año - Details on Demand — el panel inferior muestra fecha + precio bajo el cursor
📚 Didáctica · acá filtro y hover **se complementan**: el filtro acota a un año, el hover lee el día. Compará con 2a (sólo filtro) y 1 (sólo hover).
Proyecto del curso — Roaller-coaster (filtro continente + hover bidireccional)
El proyecto de montañas rusas más rápidas combina:
- Zoom & filter:
<select>continente — el mapa se reproyecta a la región elegida y se muestran sólo las top 10 de ese continente - Details on demand: hover sobre un marker (o sobre la lista lateral) resalta el otro y abre un panel con park, ubicación y velocidad
- Graphicacy: en el panel, la velocidad no se lee como número primero — se ve como una barra coloreada que crece de 0 a 250 km/h. El número aparece debajo, pero la barra ya comunicó la magnitud relativa
🎯 Proyecto · zoom & filter + details on demand + graphicacy. La versión sonora (efecto Doppler) está en T4.
Proyecto del curso — Gasto militar (slider de año + hover por país)
El gasto militar mundial combina:
- Zoom & filter (temporal): slider de año 1960→2018 que barre el mapa coroplético; puedes ver la evolución histórica (Guerra Fría, post-1989, post-2001) década a década
- Details on demand: hover sobre cualquier país → panel lateral con una barra de % del PIB sobre la escala discreta (graphicacy: el marcador se posiciona en la barra de colores, no leemos el porcentaje como texto primero)
🎯 Proyecto · los dos primeros pasos del mantra trabajando juntos. La versión con servo Arduino está en T7.
Más allá del mantra — animación temporal
Algunas interacciones útiles no encajan en los tres pasos. La animación temporal es una de ellas: no es overview, no es filtro, no es detail-on-demand. Pero comunica — porque el dato cambia con el tiempo y el ritmo de la animación es parte del mensaje.
Proyecto del curso — Migración de gaviota (animación + details narrativo)
El recorrido de la gaviota se anima mes a mes con un botón "Migrar". En cada paso:
- la rotta dibujata fino a quel punto si colora (el resto resta sbiadito)
- un panel narrativo cuenta qué está pasando (estación, contexto biológico)
- una barra de progreso (graphicacy) muestra dónde estamos en el viaje
function step(idx) {
if (idx >= TOTAL) { stopAnimation(true); return; }
Plotly.react('myMap', [...activeTracesUpTo(idx), movingMarker(idx)], layout);
updatePanel(idx); /* season text + progress bar */
setTimeout(() => step(idx + 1), 250);
}
🎯 Proyecto · la animación es la interacción. Pulsa "Migrar". Versión sonora en T4 (Tone.js mapea la latitud al tono), versión con sensor de mano en T6.
Cómo se aplica en otros proyectos del curso (sólo details on demand)
Dos proyectos donde details on demand es la única interacción que hace falta — porque el overview ya es legible y no hay nada útil que filtrar. Ambos aplican graphicacy en el panel.
Electricidad por región — la barra es el consumo
El mapa estático ya está en T2. La versión interactiva añade una sola cosa: hover sobre una región → panel con una barra horizontal que crece proporcional al consumo (no leemos "60 millones kcal/persona", vemos una barra casi llena vs. una vacía). El número aparece como referencia secundaria.
🎯 Proyecto · graphicacy puro. Pasa el mouse por una región del mapa. La versión con sensor de mano (señalar la región con el dedo) está en T6.
Mundiales de fútbol — el bar chart es la asistencia
El mapa coroplético ya está en T2. La versión interactiva añade hover → bar chart lateral con la asistencia de cada Mundial: las barras moradas son los años donde el país hospedó, las grises son los otros. El usuario lee la magnitud y el patrón temporal visualmente, sin números primero.
🎯 Proyecto · graphicacy con bar chart secundario. La versión con marcadores ArUco está en T6.
Más allá de los mapas — interactividad sobre líneas, scatter, barras
Los proyectos que vimos hasta aquí usan mapas como overview. Pero el mantra y la graphicacy se aplican igual a una línea temporal, un scatter o un bar chart. Tres ejemplos del curso, todos non-mapa.
Autos más rápidos del mundo — details on demand sobre línea + indicador
Una línea temporal (1900–2020) con cada coche que ha batido el record
mundial de velocidad. Anotaciones estáticas marcan los hitos (Mercedes 113,
Jaguar 200, Bugatti 407, Koenigsegg 458 km/h). El hover sobre cualquier
punto:
- abre un panel con foto del coche + nombre + año + comentario
- actualiza un indicador velocímetro (Plotly indicator con gauge)
que muestra la velocidad como aguja sobre escala — graphicacy puro
🎯 Proyecto · details on demand con doble graphicacy: foto (qué auto) + gauge (qué tan rápido). La versión sonora con efecto Doppler está en T4.
100m planos olímpicos — details on demand sobre scatter doble
Dos series scatter (hombres en azul, mujeres en oro) con los tiempos de cada Olimpiada de 1896 a 2020. Hover sobre un punto: - muestra foto del medallista - nombre, ciudad, año, tiempo - estrellas oro identifican los récords actuales - una "X" gris marca la descalificación por dopaje (Marion Jones 2000)
🎯 Proyecto · details on demand sobre scatter. Iconografía en los marcadores (estrella = récord, X = descalificado) ya cuenta antes del hover. Versión sonora + servo Arduino está en T7.
Viento V Región — details on demand sobre línea temporal
Velocidad del viento medida a lo largo de 2024 en la V Región. Línea simple con anotaciones estáticas en los picos (47 km/h el 13 de junio, 46 km/h el 2 de agosto). Hover sobre cualquier punto: - muestra fecha + velocidad - abre un gráfico de dirección del viento (rosa de los vientos) que visualiza el ángulo medido ese día — graphicacy con icono direccional
🎯 Proyecto · details on demand con segundo viz como detail (rosa de los vientos). La versión sonora con paisajes de viento está en T4.
Lo que viene después
En T4 añadimos audio sobre toda esta interacción: cada hover y cada clic dispara un sonido proporcional al dato. Ahí los mismos proyectos del curso aparecen en su forma sonora completa.
En T5/T6/T7 los mismos proyectos se completan con sensores físicos (cámara, marcadores ArUco, mano) y actuadores (servo Arduino). Ahí no podemos embeber la interacción (necesita hardware) — los mostramos en video, con link al código fuente.
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
📚 DidácticaHover básico — el dato debajo del cursor📚 DidácticaApple stock — hover sobre la línea (details on demand)📚 DidácticaApple stock — filtro por año (zoom & filter — menú, sin hover)📚 DidácticaApple stock — filtro por slider (zoom & filter — rango, sin hover)📚 DidácticaApple stock — los tres pasos del mantra coexisten
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaBrecha salarial — hover con panel narrativo🎯 EsperadaMapa de terremotos interactivo — detalles bajo demanda🎯 EsperadaRoaller-coaster — filtro continente + hover bidireccional🎯 EsperadaGasto militar — slider de año + hover (combina los dos pasos)🎯 EsperadaMigración de gaviota — animación temporal + details narrativo🎯 EsperadaElectricidad por región — hover con barra de consumo (graphicacy)🎯 EsperadaMundiales de fútbol — hover muestra bar chart de asistencia🎯 EsperadaAutos más rápidos — hover muestra foto + indicador de velocidad🎯 Esperada100m olímpicos — hover muestra foto + tiempo del medallista🎯 EsperadaViento V Región — hover muestra dirección + velocidad por fecha
Sonificación: audificación, earcons, iconos auditivos y alarmas inteligentes

La vista tiene un límite. Con la sonificación convertimos datos en sonido — como el monitor cardíaco — para percibir patrones, anomalías y cambios a través del oído.
En la cápsula anterior vimos cómo la interacción visual —siguiendo el mantra Overview first, zoom and filter, then details-on-demand— amplía las capacidades de las visualizaciones estáticas. Pero la vista no es el único canal disponible: cuando el espacio visual está saturado, cuando el usuario no puede mirar continuamente la pantalla, o cuando los datos cambian en tiempo real, el sonido se convierte en una alternativa o complemento muy potente.
Esta cápsula está dedicada exclusivamente a la sonificación: el arte y la ciencia de transformar datos en sonido para que el oído pueda interpretarlos.
¿Qué es la sonificación?
La sonificación es una técnica que transforma datos en sonido con el propósito de representar información de manera auditiva. Esta herramienta convierte valores numéricos o categóricos en estímulos sonoros, permitiendo que patrones o tendencias en los datos sean percibidos a través del oído. Similar a cómo las visualizaciones de datos representan información gráficamente, la sonificación emplea el sonido para interpretar y analizar datos.
En ciertos contextos la visualización puede ser insuficiente o innecesaria. Aquí es donde la sonificación ofrece una alternativa efectiva, facilitando la identificación de cambios, anomalías y patrones a través del canal auditivo. Por ejemplo, el monitoreo médico, como en el caso del monitoreo cardiaco. En situaciones críticas, el personal médico podría no tener tiempo de mirar pantallas continuamente, pero un cambio en el ritmo cardíaco puede ser captado inmediatamente a través de una señal sonora.
Objetivos y Ventajas de la Sonificación
El principal objetivo de la sonificación es comunicar información de manera auditiva, distribuyendo la carga cognitiva entre los sentidos. El oído humano es altamente sensible a variaciones en el tono (la altura o frecuencia de un sonido), volumen (la intensidad o nivel sonoro), ritmo (la temporalidad y el patrón de los sonidos) y timbre (la cualidad o color del sonido que permite distinguir entre diferentes fuentes sonoras, ej., flauta y piano), lo que permite identificar cambios en los datos con gran precisión. En situaciones donde la vista está ocupada o los datos evolucionan rápidamente, como en el monitoreo médico o sistemas de control automovilístico, el sonido ofrece una ventaja considerable.
Las ventajas de la sonificación incluyen:
- Alivio de la carga visual: Al depender del canal auditivo, se reduce la saturación del espacio visual.
- Acceso a información dinámica: En contextos donde los datos cambian rápidamente, como sistemas de alerta o monitoreo en tiempo real, el sonido permite detectar cambios de forma inmediata (ej., monitoreo cardiaco).
- Facilidad para detectar patrones sutiles: El oído es especialmente sensible a pequeñas variaciones, lo que lo convierte en una herramienta ideal para detectar anomalías en los datos.
Ese último punto —cazar lo que se sale del patrón— tiene un ejemplo célebre: la sonificación de un algoritmo de ordenamiento de burbuja defectuoso.
🔊 Pon play y vas a oír el bug. Un bubble sort sano ordena de menor a mayor: la sonificación sube de tono de forma limpia y pareja. El algoritmo con el error rompe ese barrido ascendente, y el oído pesca el tropiezo al instante — antes de que la vista alcance a contar un solo paso.
Sonic Interaction Design (SID)
El Sonic Interaction Design (SID) es una disciplina que combina el diseño de interacción con la computación musical y sonora, centrando su estudio en el uso del sonido para transmitir información, significado y emociones en contextos interactivos. A diferencia de la sonificación pasiva, donde el usuario escucha sin influir en los sonidos generados, el SID explora cómo el sonido puede integrarse en sistemas donde los usuarios participan activamente.
SID tiene aplicaciones en áreas como videojuegos, interfaces interactivas y sistemas de monitoreo en tiempo real. En estos contextos, el diseño sonoro no solo comunica información sino que también mejora la experiencia del usuario, facilitando la comprensión y respuesta rápida ante los datos.
🔊 Aquí el sonido te responde a ti, no al revés. En la sonificación pasiva el dato suena y uno escucha; en el SID el usuario actúa —golpea, inclina, aplaude— y el sistema le contesta con sonido. Estos cuatro clips del Sonification Handbook recorren esa idea, de la interacción sonora más básica al objeto que suena según cómo lo mueves.
Y un ejemplo práctico: una interacción "clap to control" donde aplaudir cambia el estado del sistema (Fig. 27.1).
Un caso más ambicioso es el Gamelunch (Fig. 27.2): una mesa de comedor sonoramente aumentada. Mientras el comensal corta, aliña la ensalada o sirve una bebida, sensores de fuerza traducen cada gesto en sonido sintetizado en tiempo real — SID en estado puro, donde la acción del usuario y la respuesta sonora forman un mismo lazo. Su giro ingenioso es el principio de contradicción: la mesa devuelve sonidos «equivocados», ajenos a lo que el gesto haría esperar, y ese choque le revela al comensal —por absurdo— cuánto se apoya, sin darse cuenta, en el sonido de cada acto cotidiano.
Sonificación directa
Un ejemplo de sonificación directa consiste en asignar propiedades del sonido a variables de datos de manera inmediata y sencilla. La representación sonora de una trayectoria es un caso típico (Fig. 27.3): los datos de posición que cambian en tiempo real se traducen en varios parámetros sonoros — el tono refleja la altura del objeto en movimiento, la espacialización reproduce el sonido de izquierda a derecha para indicar el movimiento horizontal, y el ritmo representa la velocidad del desplazamiento. La misma técnica también funciona pre-grabada, sin interacción (Fig. 27.4), cuando el objetivo es comunicar el patrón en lugar de dejarlo explorar.
Audificación
La audificación es una técnica específica de sonificación que convierte datos en sonido sin aplicar transformaciones complejas. Se suele utilizar en datos secuenciales o temporales, como señales sísmicas o biomédicas, donde los datos —en su forma original— son inherentemente audibles cuando se aceleran o se reproducen al ritmo correcto.
Las ondas sísmicas son demasiado lentas para ser audibles, pero al acelerarlas miles de veces, el oído percibe inmediatamente la diferencia entre un terremoto débil y uno catastrófico:
El estetoscopio es el ejemplo clásico de audificación: el médico escucha directamente las ondas acústicas del corazón, sin ningún mapeo intermedio.
Navegación de información a través del sonido
La navegación de datos en el contexto de la sonificación se refiere al uso del sonido para explorar y comprender grandes volúmenes de información. Así como navegamos el mundo físico continuamente para buscar información visual o táctil, el sonido puede complementar y mejorar nuestras capacidades naturales para desplazarnos en un entorno de datos abstracto.
En la navegación de datos mediante interfaces auditivas, el oído se convierte en una herramienta clave para identificar patrones, relaciones y cambios en los datos. Los sonidos proporcionan pistas sobre la estructura y el contenido de los datos, permitiendo a los usuarios "moverse" por el conjunto de información sin necesidad de una representación visual directa.
Un ejemplo claro de navegación auditiva es la interfaz Sound Torch, que utiliza el concepto de "linterna sonora" para explorar un espacio bidimensional representativo de datos. En este sistema, los usuarios pueden moverse por un entorno y emplear la "linterna" para enfocarse en los sonidos cercanos. A medida que el usuario dirige la linterna hacia distintas áreas del espacio de datos, los sonidos correspondientes se intensifican, lo que permite identificar y analizar información específica.
Iconos auditivos
Los iconos auditivos son representaciones sonoras de eventos o acciones específicas, similares a los iconos visuales en interfaces gráficas. Son sonidos cotidianos asociados a funciones comunes —como el sonido de una puerta al cerrarse para indicar que se ha completado una tarea—. Este enfoque facilita la comprensión rápida y natural de las acciones en sistemas complejos, mejorando la accesibilidad.
🔊 Escucha los cuatro: los entiendes sin que nadie te los explique, ¿cachái? Esa es la fuerza del icono auditivo — es un sonido del mundo real (agua, un grifo, grava), y por eso su significado llega solo. El reverso de la moneda: solo funciona cuando existe un sonido cotidiano que ya evoque la acción que quieres señalar.
Earcons
Los Earcons son secuencias sonoras breves y estructuradas que transmiten información en pantallas auditivas. A diferencia de los iconos auditivos, los Earcons son más abstractos y modulares, lo que permite representaciones más detalladas. Son útiles en aplicaciones donde se necesita representar una amplia variedad de eventos —como en sistemas de monitoreo de procesos— ya que pueden ser combinados y parametrizados para transmitir múltiples niveles de información (Fig. 27.5).
Alarmas Auditivas Inteligentes
Las alarmas auditivas inteligentes son sistemas diseñados para emitir señales de advertencia en situaciones críticas. A diferencia de las alarmas tradicionales, estas están integradas en entornos de trabajo complejos y se ajustan a las condiciones del contexto para evitar la sobrecarga auditiva. Un diseño eficiente incluye sonidos que son fáciles de reconocer y discriminar, permitiendo a los usuarios responder de manera rápida y efectiva ante situaciones de emergencia.
Una alarma sincrónica con el pulso arterial sigue el ritmo cardíaco del paciente. El sonido se alinea perfectamente con los latidos, proporcionando una representación sonora directa y en tiempo real del estado cardiovascular. Útil en contextos médicos donde se requiere monitorear de manera constante el pulso sin depender de visualizaciones.
Una alarma de despertar se activa cuando el paciente comienza a despertarse. El sonido alerta al personal sanitario del cambio sin necesidad de observación visual constante.
Aplicaciones en Tecnología Asistiva
La sonificación juega un papel crucial en la tecnología asistiva, especialmente para personas con discapacidades visuales. Al transformar información visual en señales sonoras, estas tecnologías mejoran la accesibilidad y permiten que los usuarios interpreten datos de manera precisa. Por ejemplo, los lectores de pantalla convierten el texto en sonido, mientras que otros sistemas proporcionan orientación espacial auditiva, facilitando la navegación.
Uso de voz en la visualización de información
En la representación de datos, los spearcons, la mensajería de voz automatizada y la síntesis de texto a voz (TTS) ofrecen ventajas significativas en situaciones donde el sonido puede mejorar la comprensión o donde la carga visual es alta.
- Spearcons: fragmentos acelerados de palabras habladas. Útiles para indicar eventos o cambios importantes en los datos. Permiten recibir información auditiva de manera rápida, sin recurrir al texto o gráficos.
- Mensajería de voz: uso automatizado de mensajes de voz mediante síntesis o grabaciones predefinidas, en sistemas de monitoreo o control para transmitir información precisa en tiempo real. Estos mensajes se activan automáticamente cuando ocurren eventos críticos.
- Síntesis de texto a voz (TTS): tecnología particularmente útil para hacer accesibles los datos textuales a personas con discapacidades visuales, o cuando se requiere una interpretación rápida de información numérica o textual sin apartar la atención de otras tareas visuales.
Estas tecnologías auditivas no solo complementan la representación de los datos, sino que también optimizan la forma en que los usuarios pueden interactuar con ellos, haciendo que la experiencia sea más ágil, accesible y efectiva.
T4. Sonificación: MP3, Tone.js, WebAudioFont y Web Speech API
Datos que suenan: del MP3 al instrumento real, todo desde el navegador
Los gráficos se ven. Pero también pueden sonar — y a veces el oído entiende patrones que el ojo se pierde. MP3, Tone.js, Web Audio: tres puertas a la información audible.
Del gráfico interactivo al sonido
En T3 hicimos los proyectos del curso interactivos: hover, filtros, animación. Aquí los mismos viz los hacemos sonar.
Cinco estrategias para sonificar
- Iconos sonoros — un MP3 pre-grabado por categoría (lluvia, viento, …)
- Tonos sintetizados con Tone.js — flexibles, suenan a sintético
- Soundfonts (WebAudioFont) — instrumentos reales con control MIDI
- Voz (TTS, Web Speech API) — narrar valores en palabras
- Combinaciones — la práctica real, donde se mezclan varias
Empezamos por las didácticas para ver cada técnica aislada. Después el ejemplo del curso (la casita que tiembla). Después la versión "contraten dos personas" que combina varias estrategias para contar una historia. Y finalmente los proyectos estudiantes, organizados por estrategia.
Versiones didácticas — cada técnica aislada
Estrategia 1 — Iconos sonoros (MP3)
Un MP3 pre-grabado por categoría. Es la más simple: hace falta tener el archivo y reproducirlo es una línea de JS.
Conseguir el audio
- Freesound.org — biblioteca Creative Commons
- YouTube → MP3 con y2mate.is (con cabeza)
- Grabar con el celular y traer al computador
Editar: Tenacity
Tenacity (fork libre de Audacity) recorta, mezcla, normaliza, exporta a MP3 / WAV (Fig. 28.1). Gratuito y multiplataforma.
Reproducir
const audio = new Audio("lluvia-fuerte.mp3");
audio.play();
Demo didáctica — dos barras, dos MP3
📚 Didáctica · solo el mecanismo
plotly_click + new Audio().play().Estrategia 2 — Tonos sintetizados (Tone.js)
Cuando los datos varían continuamente y quieres que cada valor tenga su propia altura, los MP3 quedan cortos: harían falta hartos. Tone.js sintetiza el tono en el navegador, en tiempo real.
<script src="https://unpkg.com/tone"></script>
// IMPORTANTE: el navegador requiere un gesto del usuario antes de
// reproducir audio. Encerrá Tone.start() en un click:
document.getElementById('start').addEventListener('click', async () => {
await Tone.start();
});
const synth = new Tone.Synth().toDestination();
synth.triggerAttackRelease('C4', '8n'); // Do central, corchea
Mapear altura visual ↔ altura sonora
function mapToFreq(value, min, max) {
return 200 + ((value - min) / (max - min)) * 600; // [200..800] Hz
}
MIDI — el lenguaje musical
MIDI numera cada nota: Do central = 60, una octava arriba = 72, cada semitono = 1. Mapear a MIDI en lugar de Hz hace que las diferencias se perciban musicalmente — el oído reconoce intervalos:
function mapToMidi(v, min, max) {
return 60 + Math.round(((v - min) / (max - min)) * 24); // 2 octavas
}
El esquema Fig. 28.2 resume el mapeo de punta a punta: cada barra del gráfico se proyecta sobre el teclado, y la tecla que alcanza fija el número MIDI que suena. Barra más alta, tecla más aguda.

Demo didáctica — please-hire básico
El mismo dataset que la viñeta de T1 (tickets recibidos vs procesados),
pero sin narrativa. Click en cualquier barra → suena la nota MIDI
proporcional al valor (triangle para Received, sine para Processed).
"Play Sequence" recorre los 12 meses.
function mapValueToMIDI(v, inMin, inMax, outMin, outMax) {
return Math.round((v - inMin) * (outMax - outMin) / (inMax - inMin) + outMin);
}
document.getElementById('myDiv').on('plotly_click', d => {
const midiNote = mapValueToMIDI(d.points[0].y, minValue, maxValue, 45, 81);
const synth = new Tone.Synth({ oscillator: { type: 'sine' } }).toDestination();
synth.triggerAttackRelease(Tone.Frequency(midiNote, "midi"), "0.5");
});
📚 Didáctica · sólo el mecanismo Tone.js sobre el mismo dataset. Comparála con el combinado más abajo donde se cuenta una historia.
Estrategia 3 — Instrumentos reales (WebAudioFont)
Tone.js suena sintético. Para que suene a piano de verdad, guitarra, trompeta, usamos WebAudioFont (surikov/webaudiofont), una librería con cientos de instrumentos.
<script src="https://surikov.github.io/webaudiofontdata/sound/0730_FluidR3_GM_sf2_file.js"></script>
const audioCtx = new AudioContext();
const player = new WebAudioFontPlayer();
player.queueWaveTable(audioCtx, audioCtx.destination,
_tone_0730_FluidR3_GM_sf2_file, 0, 60, 1); // Do central, 1 segundo
Demo didáctica — Apple stock + piano
Botón "Play data": el piano recorre la serie temporal del precio de Apple, una nota por día, altura proporcional al precio.
📚 Didáctica · técnica funcional pero la línea ya se ve. Sirve para aprender, no es nivel de proyecto.
Apple + filtros + sonificación — más didáctico
Los mismos demos de filtro de T3 con sonificación encima. Filtrar la serie y reproducirla con piano: la técnica funciona pero el filtro y el sonido son decoración — no comunican nada que el gráfico no diga.
📚 Didáctica · combinaciones técnicas. Útil para aprender a integrarlas, pero el filtro y el sonido aquí son decoración: no comunican nada que el gráfico filtrado solo no comunique.
Estrategia 4 — Voz (Web Speech API)
const u = new SpeechSynthesisUtterance("Dos personas renunciaron en mayo");
u.lang = "es-es";
window.speechSynthesis.speak(u);
Sola es útil para accesibilidad y narración, pero su fuerza real aparece combinada con las otras estrategias (lo veremos abajo en el combinado).
Ejemplo del curso — la casita que tiembla (terremotos)
El mapa interactivo de T3 con audio encima. Tres MP3 (low.mp3,
medium.mp3, high.mp3) que se mezclan según la magnitud — no se
elige uno, los tres suenan a la vez con volúmenes distintos:
const highAudio = new Audio("high.mp3");
const mediumAudio = new Audio("medium.mp3");
const lowAudio = new Audio("low.mp3");
myPlot.on('plotly_click', data => {
const m = terremotos[data.points[0].pointIndex].Magnitud;
highAudio.volume = Math.max(0, Math.min(1, m - 7.9));
mediumAudio.volume = Math.max(0, Math.min(1, m - 6.9));
lowAudio.volume = Math.max(0, Math.min(1, m - 5.9));
[highAudio, mediumAudio, lowAudio].forEach(a => {
a.currentTime = 0; a.play();
});
});
Truco: la mezcla por volúmenes da una transición orgánica entre magnitudes — un terremoto 7.5 suena distinto a uno 8.5 sin saltos.
🎯 Proyecto · el sonido recrea físicamente la experiencia del terremoto. La casita que tiembla, en el navegador. Aquí la sonificación no decora: cuenta.
Combinar estrategias — "Contraten dos personas"
El demo más rico de la cápsula. Sobre el gráfico de tickets de T1, el botón "▶ Cuéntame en sonidos" dispara una secuencia que combina varias estrategias para contar una pequeña historia:
- una línea roja vertical que avanza mes a mes (visual)
- un tono sintético FM (Tone.js, E2) cuya frecuencia baja según la diferencia entre tickets recibidos y procesados
- en mayo, una voz (SpeechSynthesis, E4) anuncia "dos personas renunciaron en mayo"
- al mismo tiempo, un MP3 de puerta cerrándose (icono sonoro, E1) suena dos veces — las dos personas que se fueron
- al final, una caída tonal lenta (Tone.js, E2 otra vez) representa la imposibilidad de recuperarse, y la voz cierra: "no podemos recuperarnos desde entonces"
// Las tres estrategias trabajan juntas en el mismo tick
synth.triggerAttackRelease(freqByDiff, "4n"); // E2: tono
if (mes === 4) {
doorClosing.currentTime = 0; doorClosing.play(); // E1: icono
speak("dos personas renunciaron en mayo"); // E4: voz
}
🎯 Proyecto · combina tono + voz + icono sonoro al servicio de la narrativa. La sonificación aquí amplifica el mensaje de la viñeta original.
Proyectos del curso — organizados por estrategia
Cada proyecto del curso eligió la estrategia que encaja con el dato y con la experiencia que querían provocar. Acá los iframes están en vivo — no hay videos: la sonificación se escucha sólo activándola.
Estrategia 1 (MP3 / iconos sonoros)
Lluvia en Chile — MP3 naturales por intensidad
Tres MP3 de lluvia natural (suave, media, fuerte) cruzados con las precipitaciones por región. Click en una región → suena la intensidad de su lluvia. El sonido elegido es mimético: la lluvia suena a lluvia.
🎯 Proyecto · sonificación con significado emocional. Conecta el dato abstracto con la sensación física de estar bajo esa lluvia.
Viento V Región — paisajes sonoros por categoría
Brisa para días suaves, ventiscas de campo para días intensos, naturaleza ambiente para los medianos. Mapeo discreto (3 categorías) pero culturalmente reconocible.
🎯 Proyecto · paisaje sonoro como dimensión de comprensión.
Mundiales fútbol — cheers proporcional a asistencia
Hover sobre un país → el público del estadio aplaude. El volumen de los cheers crece con la asistencia del Mundial que ese país hospedó. Cuando un país no tiene datos, suena un "no encontrado".
🎯 Proyecto · MP3 ambient (cheer del público) + modulación de volumen. Conecta dato (asistencia) con experiencia (estar en el estadio).
Electricidad por región — pulso que se acelera
MP3 de un pulso que se reproduce a intervalo proporcional al consumo. Más consumo → pulso más rápido. La velocidad de repetición codifica el dato — variación temporal del mismo MP3.
🎯 Proyecto · MP3 corto + modulación de la frecuencia de repetición. Cabe en estrategia 1 con un giro temporal.
100m olímpicos — pasos de carrera con tempo
MP3 loop de pasos corriendo. Click en un medallista → el loop se
reproduce con playbackRate proporcional a su tiempo de carrera. Al
final más rápido → loop más acelerado.
🎯 Proyecto · MP3 +
playbackRate. La velocidad mecánica del audio refleja la velocidad humana del corredor.Gasto militar mundial — 6 niveles MP3 discretos
Click en un país → suena uno de seis MP3, según el bucket de % PIL. Más serie discreta del mundo: una alarma diferente para cada nivel (de aviso suave a alarma de guerra).
🎯 Proyecto · iconos sonoros discretos por bucket. Comunican jerarquía de gravedad sin números.
Estrategia 2 (Tono sintetizado)
Autos más rápidos — oscilador con rampa de frecuencia
Click en un coche → un Tone.Oscillator parte de 30 Hz y hace una rampa
lineal hasta el doble de la velocidad del coche en Hz, en 3 segundos.
El crescendo del tono encarna la aceleración del coche.
🎯 Proyecto · sintético justificado — un MP3 grabado no captura la rampa lineal de aceleración.
Combinación — Tono + Voz (Estrategia 2 + 4)
Cuando el sonido sintético solo no basta, una voz narrante después da contexto: el oído percibe primero la magnitud sonora, luego el cerebro recibe la información detallada en palabras.
Montañas rusas — Doppler sintético + voz narrante
Click en un coaster: primero un tono sintético tipo Doppler (sube y baja imitando el paso del coaster frente al oído, frecuencia mapea velocidad). Cuando el Doppler termina, una voz (Web Speech API) lee nombre, ubicación, parque y velocidad. Sintético + voz: el tono emociona, la voz informa.
function narrarYSonificar(c) {
playDoppler(c.Speed, () => { // E2: Web Audio
speechSynthesis.speak(new SpeechSynthesisUtterance(
`La montaña rusa ${c.coaster_name} está en ${c.Park}. ` +
`Su velocidad máxima es de ${c.Speed} kilómetros por hora.`
)); // E4: voz
});
}
🎯 Proyecto · combina tono sintético (E2, imita el paso físico) + voz (E4, da los datos en palabras). El sintético no existe como MP3 — se construye en tiempo real.
Migración de gaviota — tono por latitud + voz por estación
La animación temporal de T3 ahora habla. Mientras la gaviota recorre la rotta: - un tono Tone.js cuya frecuencia mapea la latitud suena en cada paso - cuando cambia la estación, una voz (Web Speech API) anuncia "Verano", "Otoño", …
synth.triggerAttackRelease(latitudeToFreq(lat), '100n');
if (currentSeason !== seasonName) speak(seasonName); // estrategia 4
🎯 Proyecto · tono continuo (E2) + voz (E4). El sonido marca el ritmo del viaje, la voz da estructura narrativa.
Tres contextos donde la sonificación aporta
- Emocionar — música, narrativa, paisajes sonoros (lluvia, viento, casita que tiembla)
- Amplificar cognición — alarmas, monitoreo (médico, networking)
- Accesibilidad — discapacidad visual, narración de gráficos
Si tu proyecto no encaja en ninguno de los tres, probablemente la sonificación está sobrando.
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
📚 DidácticaDos barras → dos MP3 — iconos sonoros (estrategia 1)📚 Didácticaplease-hire básico — Tone.js, dos barras que suenan (estrategia 2)📚 DidácticaApple stock — WebAudioFont, instrumento real (estrategia 3)📚 DidácticaApple stock + filtro menú + sonificación📚 DidácticaApple stock + doble slider + sonificación
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaTerremotos — la casita que tiembla (mix de 3 MP3 por magnitud)🎯 EsperadaContraten dos personas — Tone.js + voz + MP3 puerta (cuenta una historia)🎯 EsperadaLluvia en Chile — MP3 naturales por intensidad (E1)🎯 EsperadaViento V Región — paisajes sonoros por categoría (E1)🎯 EsperadaMundiales fútbol — cheers proporcional a asistencia (E1)🎯 EsperadaElectricidad por región — pulso que se acelera con consumo (E1)🎯 Esperada100m olímpicos — passi de carrera con tempo (E1)🎯 EsperadaGasto militar mundial — 6 niveles MP3 discretos (E1)🎯 EsperadaAutos más rápidos — oscilador Tone.js con rampa (E2)🎯 EsperadaMontañas rusas — Doppler sintético + voz narrante (E2 + E4)🎯 EsperadaMigración de gaviota — Tone.js + voz por estación (E2 + E4)
Prototipado: virtual, mixto y físico — fidelidad y reconfigurabilidad

Diseñar en la pantalla está bien para empezar. Pero antes de invertir cien horas en programar la versión final, hay que prototipar. Un prototipo es una pregunta hecha objeto.
¿Qué es un prototipo?
Un prototipo es una versión temprana y simplificada de una representación visual de información. Imagina que estás diseñando un panel de control para visualizar métricas: antes de desarrollar la interfaz final, creas una representación básica para visualizar cómo se presentará la información. Esto permite explorar diferentes enfoques y evaluar la efectividad de la visualización antes de invertir en su desarrollo completo. Este proceso se conoce como prototipado y es fundamental en el diseño de visualizaciones de datos y la fisicalización de información.
Tipos de Prototipado en Visualización de Datos
El prototipado en visualización de datos puede adoptar diversas formas, según el tipo de datos que se estén representando y las interacciones que se deseen explorar. A continuación, examinamos tres enfoques principales:
- El prototipado virtual se centra en crear representaciones digitales de los datos. Utiliza herramientas de visualización para simular cómo se presentarán los datos en un entorno interactivo. Esto permite realizar pruebas rápidas y obtener retroalimentación sobre la navegación y la efectividad de la visualización. Por ejemplo, al crear un gráfico interactivo, se pueden ajustar los elementos visuales y analizar cómo los usuarios interactúan con ellos.
- El prototipado mixto combina elementos físicos y virtuales para crear una experiencia de visualización enriquecida. Por ejemplo, un prototipo físico que integre realidad aumentada (AR) puede superponer datos digitales sobre un objeto físico, permitiendo a los usuarios interactuar con la información de manera más tangible. Este enfoque es especialmente útil en la fisicalización de datos, donde el objetivo es hacer que los datos sean más accesibles y comprensibles a través de experiencias interactivas.
- El prototipado físico implica la creación de modelos tangibles que representan datos o conceptos. Por ejemplo, maquetas tridimensionales que visualizan patrones de datos complejos. Estos prototipos pueden ser interactivos si incorporan sensores y actuadores programables, permitiendo a los usuarios explorar los datos a través de interacciones físicas. Esto es fundamental en la fisicalización de datos, ya que transforma la información abstracta en experiencias concretas que pueden ser tocadas y manipuladas.
🧩 Tres tipos, tres preguntas. Si un prototipo es una pregunta hecha objeto, el tipo que elijas depende de qué quieres averiguar: el virtual responde «¿cómo se navega?», el físico «¿cómo se siente en la mano?», y el mixto «¿cómo se funde el dato con el espacio real?».
Estos tres enfoques se ilustran lado a lado en el ejemplo (Fig. 29.1): a la izquierda un prototipo virtual, en el centro uno mixto y a la derecha uno físico.
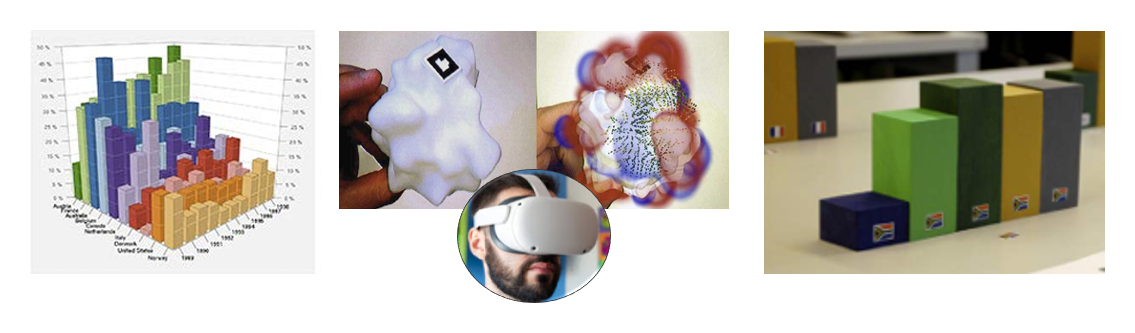
Técnicas de Prototipado Rápido en Visualización de Datos
El prototipado rápido es crucial para iterar sobre ideas y conceptos en la visualización de datos. Algunas técnicas incluyen:
- Bocetos en Papel: Dibujos rápidos que capturan ideas y conceptos visuales. Son ideales para explorar representaciones de datos de manera ágil y comunicar ideas iniciales sin preocuparse por los detalles técnicos.
- Maquetas Físicas: Modelos tridimensionales que permiten a los usuarios interactuar con los datos de manera tangible. Al integrar sensores, estas maquetas pueden responder a las interacciones, ofreciendo una evaluación más rica de la ergonomía y el tamaño en el contexto de la visualización de datos.
- Simulaciones en Software: Prototipos digitales que permiten probar flujos de usuario y evaluar cómo los usuarios navegan por los datos. Son especialmente útiles para obtener comentarios realistas sobre la interacción y el diseño de la visualización.
La comparación (Fig. 29.2) muestra estas tres técnicas en paralelo: una maqueta física, un boceto en papel y un mockup de software.
Niveles de Fidelidad en Prototipos de Visualización
La fidelidad del prototipo es un factor clave en la visualización de datos. No todos los prototipos necesitan ser precisos y detallados. Dependiendo de la etapa del proyecto y los objetivos, se pueden emplear diferentes niveles de fidelidad:
- Los prototipos de baja fidelidad son rápidos y esquemáticos, enfocándose en la idea general de la visualización sin preocuparse por los detalles específicos. Son útiles para explorar múltiples conceptos, obtener retroalimentación temprana y ahorrar tiempo en las fases iniciales del diseño de visualización.
- Los prototipos de fidelidad media ofrecen más detalles que los bocetos, pero no alcanzan la complejidad de un producto final. Permiten refinar conceptos, evaluar flujos de usuario con mayor realismo y comunicar ideas visualmente con cierto grado de interactividad.
- Los prototipos de alta fidelidad son versiones detalladas y cercanas al producto final. Incluyen elementos visuales y funcionales que permiten evaluar la experiencia del usuario en profundidad. Son ideales para presentar a inversores o partes interesadas y para validar detalles específicos de la visualización.
🪜 Baja fidelidad temprano, alta fidelidad tarde. El error clásico del principiante es pulir demasiado pronto: montar un prototipo de alta fidelidad sólo para explorar ideas cuesta horas y, peor, te enamora del producto antes de validarlo. Mientras más temprana la etapa, más esquemático conviene el prototipo.
El esquema (Fig. 29.3) resume los tres niveles de fidelidad con un ejemplo representativo de cada uno (consulta la presentación para más ejemplos).

Factores Clave: Reconfigurabilidad y Nivel de Habilidad
Al elegir el tipo de prototipo, es esencial considerar factores como:
- Reconfigurabilidad: La capacidad del prototipo para ser reordenado o modificado en nuevas configuraciones. Esto permite probar diferentes representaciones de datos sin comenzar desde cero, facilitando la exploración de múltiples enfoques visuales.
- Nivel de Habilidad: El nivel de destreza técnica requerido para crear o manipular el prototipo. Los prototipos de baja fidelidad suelen requerir menos habilidades técnicas, mientras que los de alta fidelidad pueden necesitar conocimientos más avanzados.
🧭 Lee el diagrama como una brújula, no como teoría. Antes de construir nada, ubica tu proyecto en el plano: si vas a iterar harto, busca un prototipo de alta reconfigurabilidad y baja barrera técnica —kits de construcción, cartón—. Deja los métodos caros de rehacer para cuando el diseño ya esté casi cerrado.
El diagrama (Fig. 29.4) cruza ambos factores —reconfigurabilidad y nivel de habilidad técnica requerida— y ubica los distintos tipos de prototipo en el plano resultante.

Interactividad en Visualización de Datos Físicas e Interactivas
Más allá del nivel de fidelidad, la interactividad del prototipo es una decisión clave que afecta tanto la complejidad como las preguntas que el prototipo puede responder. Cada modalidad ilumina aspectos distintos de la experiencia del usuario.
Prototipos en Pantalla
Los prototipos en pantalla son representaciones digitales que pueden ir desde maquetas interactivas simples (Figma, InVision) hasta simulaciones de alta fidelidad cercanas al producto final. Sus tres ventajas concretas:
- Probar flujos de usuario completos — el usuario navega como en el producto real, lo que permite identificar puntos de fricción.
- Evaluar navegación e interacción — facilita pruebas sobre si la información se presenta de manera clara.
- Obtener feedback realista — el usuario interactúa y comenta sobre la experiencia, no sobre una imagen estática.
Prototipos Físicos
Los prototipos físicos son modelos tangibles construidos con cartón, espuma, plástico, o materiales reciclados. Se vuelven interactivos al integrar sensores y actuadores programables (servos, parlantes, vibradores, LEDs). Ejemplos típicos en InfoVis: maquetas de dispositivos donde se mostrarán datos, prototipos de instalaciones para museos, modelos arquitectónicos que integran visualización. Sus ventajas son específicas:
- Evaluar ergonomía y experiencia táctil — el peso, la textura y el tamaño físico importan, y sólo se pueden probar en el cuerpo.
- Simular movimientos y acciones físicas — qué pasa cuando el usuario toca, agita, gira el dispositivo.
- Obtener feedback de uso real — el contexto físico (luz, ruido, otras personas alrededor) es difícil de simular en pantalla.
Prototipado Offline y Online
El proceso de prototipado también se puede partir en dos modos: offline y online.
El prototipado offline usa lápiz, papel, cartón, cinta adhesiva, recortes. Su ventaja es la velocidad y el bajísimo costo de modificar: arrancas un papel, dibujas otro, en cinco minutos tienes una alternativa para comparar. Es ideal para los primeros pasos de materialización de una idea y para compartir visiones iniciales con el equipo sin compromiso.
El prototipado online, en cambio, lleva el diseño a una dimensión más avanzada usando simulaciones interactivas con software o hardware específico. Ofrece dos cosas que el offline no puede: probar flujos de usuario y funcionalidades en un entorno cercano al producto final, y obtener insights sobre la viabilidad técnica (¿se puede construir esto en hardware real? ¿el sensor responde bien?).
La regla práctica: empezar offline y muy a mano, y pasar a online sólo cuando las preguntas de diseño ya no se pueden responder en papel.
Sensores y actuadores multipropósito: cámara, micrófono, parlante, pantalla

Para que un prototipo físico sea interactivo, necesita dos cosas: sentidos para percibir (sensores), y manos para actuar (actuadores). Y lo mejor: tu celular ya los tiene todos.
Cómo crear visualizaciones físicas e interactivas
Una visualización física e interactiva no se limita a mostrar datos; también permite que el prototipo tome decisiones a partir del entorno y que el usuario participe activamente. Para lograrlo, todo sistema combina dos clases de componentes:
- Los sensores detectan cambios en el entorno físico (movimiento, luz, sonido, proximidad) y los convierten en datos digitales que el sistema puede procesar.
- Los actuadores introducen cambios en el entorno físico en respuesta a esos datos: mover un motor, encender una luz, reproducir un sonido, vibrar.
🧠 Un sistema interactivo funciona como un cuerpo. Los sensores son los sentidos —vista, oído, tacto— que captan el mundo; el procesador es el cerebro que decide; los actuadores son las manos y la voz que lo modifican. La sinergia de las tres partes es lo que vuelve viva a una InfoVis física, en vez de un mero objeto decorativo.
La misma anatomía se reconoce en una persona (Fig. 30.1) y en una máquina (Fig. 30.2).


📱 Tu celular ya trae todos los sensores y actuadores que un prototipo necesita. No hace falta comprar hardware suelto: basta con el aparato que ya llevas en el bolsillo.
El esquema (Fig. 30.3) reparte los componentes del smartphone en dos familias: en azul los sensores —cámara, micrófono, GPS, giroscopio, acelerómetro y el tacto de la pantalla—; en verde los actuadores —parlantes, pantalla y vibrador—.

Sensores Multipropósito
Los sensores multipropósito son dispositivos diseñados para detectar y medir una amplia variedad de cambios en el entorno físico, transformando esas observaciones en datos utilizables. A diferencia de los sensores específicos, que tienen un propósito limitado (como medir la temperatura o la presión), los sensores multipropósito pueden adaptarse a diversas aplicaciones, lo que les permite captar información de manera más dinámica en InfoVis físicas e interactivas. Estos sensores a menudo requieren procesamiento de datos y técnicas de inteligencia artificial (IA) para interpretar las señales y actuar de manera efectiva. Por ejemplo, el uso de bibliotecas como Google MediaPipe permite el análisis de video y la detección de características en tiempo real, ampliando las capacidades de los sensores.
A continuación, se detallan algunos tipos de sensores multipropósito:
Las cámaras pueden detectar una variedad de elementos en el ambiente, incluyendo:
- Movimiento en el ambiente: Identifican cambios en la posición de objetos o personas, facilitando interacciones dinámicas.
- Luz: Miden la intensidad de la luz, lo que puede influir en la presentación visual de la información.
- Presencia: Detectan la presencia de personas en el área, activando la visualización solo cuando hay interacción.
- Marcadores ARUCO: Se utilizan para el seguimiento preciso de objetos en entornos de realidad aumentada.
- Reconocimiento facial: Pueden identificar caras, expresiones faciales y la posición de puntos salientes (landmarks), lo que permite adaptar la experiencia del usuario.
- Seguimiento de cuerpos: Identifican la posición y los puntos salientes de los cuerpos, permitiendo interacciones más personalizadas.
- Seguimiento de manos: Detectan la posición y los puntos salientes de las manos, facilitando interacciones táctiles y gestuales.
Los micrófonos son esenciales para captar el entorno sonoro y pueden detectar:
- Cantidad de ruido: Proporcionan una aproximación de los niveles de sonido en el ambiente.
- Habla: Permiten la interacción verbal y pueden integrarse en sistemas de reconocimiento de voz.
- Eventos de sonidos: Se utilizan para clasificar y responder a diferentes tipos de sonidos en el entorno.
Combinación de Sensores
La potencia de un prototipo crece cuando se combinan sensores complementarios para capturar fenómenos que ninguno por sí solo podría medir bien:
- Acelerómetros — miden aceleración lineal y, indirectamente, la inclinación de un dispositivo respecto a la gravedad. Detectan agitaciones, golpes, rotaciones bruscas.
- Giroscopios — miden velocidad angular en los tres ejes. Combinados con el acelerómetro, dan la orientación 3D completa del dispositivo en el espacio.
La combinación acelerómetro+giroscopio es la que permite, por ejemplo, que un celular sepa si está en horizontal o vertical, si gira sobre la mano, o si está siendo sacudido como un sismo. Cualquier prototipo que requiera tracking de posición en 3D —juegos, navegación, fisicalización de movimiento— depende de esta combinación.
Actuadores Multipropósito
Los actuadores multipropósito son dispositivos que permiten a los sistemas de InfoVis interactuar con el entorno físico. A diferencia de los actuadores específicos, que tienen una función concreta (como encender una luz o mover un motor), los actuadores multipropósito pueden adaptarse a diferentes necesidades de interacción y respuesta. Estos dispositivos son fundamentales para traducir los datos procesados en acciones tangibles que enriquecen la experiencia del usuario.
A continuación, se presentan algunos ejemplos de actuadores multipropósito:
Los parlantes son actuadores que pueden:
- Reproducir sonidos: Proporcionan retroalimentación auditiva en respuesta a interacciones del usuario.
- Reproducir notas musicales: Se pueden usar para crear experiencias interactivas basadas en la música.
- Reproducir habla: Permiten la comunicación verbal entre el sistema y el usuario.
Las pantallas son herramientas visuales clave en la InfoVis que pueden:
- Mostrar visualizaciones de datos: Facilitan la representación gráfica de información de manera efectiva y atractiva.
- Reproducir el comportamiento de componentes físicos: Pueden simular el funcionamiento de lámparas, interruptores y perillas (gracias al sensor táctil), proporcionando una experiencia interactiva realista.
La pantalla, gracias al sensor táctil, puede incluso reproducir el comportamiento de controles físicos tradicionales como interruptores y perillas (Fig. 30.4).

Existen herramientas como Protobject Framework que permiten prototipar de manera rápida y sencilla sistemas físicos interactivos para visualización de información, utilizando los sensores y actuadores de los smartphones.
Ejemplos de Prototipos de InfoVis Físicas e Interactivas
Para aterrizar la teoría, conviene ver siete prototipos concretos donde sensores y actuadores cobran sentido. Cada uno responde a una pregunta de visualización con la combinación mínima de hardware que la hace posible.
📱 Siete prototipos de verdad — cada uno con su video. Lo que sigue no son ideas en el papel: son sistemas que funcionan, construidos con los sensores y actuadores del celular. Fíjate cómo, en cada caso, bastan dos o tres componentes para volver tangible una harto interesante pregunta de datos.
Visualización del Consumo de Energía
Una cámara cuenta cuántas personas hay en la habitación mediante detección facial o reconocimiento de movimiento, y los datos de consumo eléctrico se ajustan en tiempo real según ese número. La pregunta: ¿cómo cambia el consumo per cápita con la ocupación? (Fig. 30.5)
Regulación de Temperatura
Un giroscopio y un acelerómetro montados sobre una puerta detectan su apertura y el grado de la misma. Cuando la puerta se abre, el sistema calcula el descenso de temperatura proyectado y lo dibuja en un gráfico en tiempo real. La pregunta: ¿cuánto calor pierdo si dejo la puerta entreabierta? (Fig. 30.6)
Simulación de Terremotos
Una casita LEGO con un acelerómetro adentro; el usuario la sacude y el sistema busca, en una base histórica de sismos chilenos, cuál se acerca más en intensidad al movimiento generado. La pregunta: ¿cuánto se siente realmente un terremoto de magnitud 7,5? (Fig. 30.7)
Filtrado de Datos por Distancia
La cámara mide la proximidad del usuario a la pantalla y ajusta automáticamente el zoom de la visualización (más cerca, más detalle; más lejos, vista general). Implementa el mantra de Shneiderman con el cuerpo. (Fig. 30.8)
Predicciones del Precio del Bitcoin
La cámara reconoce gestos, expresiones faciales y posición de las manos; un acelerómetro detecta la inclinación de objetos físicos. Según las reacciones del usuario, el sistema muestra una predicción optimista, neutral o pesimista. La pregunta: ¿cómo influye el sesgo emocional del lector en la lectura de proyecciones? (Fig. 30.9)
Control de Exportaciones de Productos
Productos físicos (porotos, té, atún) marcados con códigos ARUCO se mueven sobre una superficie; la cámara los rastrea y el gráfico de exportaciones por país se reordena en tiempo real. La pregunta: ¿qué pasa con el ranking si pongo el foco en este producto? (Fig. 30.10)
Interacción con un Mapa Físico
Un mapa impreso, una cámara que sigue el dedo índice del usuario, y un parlante que dice en voz alta el monto exportado de frutas del país tocado. La pregunta: ¿se puede explorar un dataset geográfico sin pantalla? (Fig. 30.11)
Cada ejemplo es minimalista por diseño: una pregunta, dos o tres sensores, una respuesta tangible. Combinaciones más complejas (cámara + acelerómetro + parlante) sólo se justifican cuando la pregunta lo exige. La regla de oro: el hardware sirve a la pregunta, no al revés.
Fisicalización para comunicación, educación y accesibilidad

Imaginen un mundo donde los datos no viven solo en pantallas, donde se tocan, se sienten en las manos. Eso es fisicalización de datos. Y existe desde hace siglos.
Fisicalización para comunicación y educación
La fisicalización de datos se utiliza en comunicación y educación para transformar datos abstractos en objetos físicos que las personas pueden ver, tocar y manipular. Esto permite a educadores y comunicadores presentar la información de manera más clara y tangible, ayudando al público a comprender conceptos complejos de forma más intuitiva.
✋ Enseñar con las manos no es nuevo — tiene siglos. De los modelos sólidos de geometría de George Adams a los bloques LEGO de Hans Rosling, el gesto es siempre el mismo: volver agarrable una idea abstracta. Y lo que las manos manipulan, la cabeza lo retiene mucho mejor.
Dos ejemplos clásicos (Fig. 31.1) ilustran esta tradición: en el siglo XVIII, George Adams construyó modelos sólidos de geometría tridimensional para enseñar matemáticas, y más tarde Dorothy Hodgkin creó modelos moleculares físicos para explicar descubrimientos científicos como la estructura de la penicilina.

En tiempos modernos, Hans Rosling popularizó el uso de objetos cotidianos como bloques LEGO y rollos de papel para ilustrar temas como el crecimiento de la población mundial Fig. 31.2. Estos métodos no solo capturan la atención del público, sino que también refuerzan la comprensión a través de la interacción física (Fig. 31.3).

En resumen, la fisicalización en ámbitos educativos y de comunicación ofrece una forma accesible e inclusiva de aprender y compartir conocimientos e involucrar a las personas de manera más profunda.
Fisicalización para la accesibilidad
La fisicalización de datos es una herramienta prometedora para mejorar el acceso a la información para personas con discapacidades visuales. Al convertir datos abstractos en objetos físicos que pueden ser tocados y manipulados, la fisicalización ofrece nuevas formas de representar información de manera tangible y accesible, más allá de los medios visuales tradicionales. En esta sección, se exploran sistemas tradicionales y recientes desarrollos en tecnologías de fisicalización que apoyan la accesibilidad para personas con discapacidad visual.
✋ Para un lector ciego, lo físico no es un extra: es la única puerta. Un gráfico en pantalla simplemente no existe sin la vista. Llevar el dato al relieve, al pin, al objeto que se manipula es lo que vuelve la información de verdad accesible — y esta sección lo recorre, de lo más artesanal a lo más tecnológico.
Sistemas de baja tecnología
Gráficos Táctiles: Desde el siglo XIX, los gráficos táctiles han sido utilizados para representar imágenes, mapas y gráficos en papel en relieve, permitiendo que las personas con discapacidad visual puedan explorar contenido visual de forma háptica.
- Uso: Ampliamente utilizados en escuelas, estos gráficos proporcionan una forma de presentar información compleja, como mapas temáticos y gráficos estadísticos, mediante el tacto.
- Limitaciones: Aunque útiles, los gráficos táctiles están restringidos a medios 2D, lo que limita la complejidad de la información que se puede transmitir.
Tableros de Gráficos: Los tableros de gráficos son herramientas simples que consisten en tablas de corcho con líneas en relieve. Estudiantes pueden colocar pines y usar bandas elásticas para crear gráficos táctiles 2D.
- Uso Educativo: Estos tableros permiten a los estudiantes ciegos construir y manipular sus propios gráficos, promoviendo el aprendizaje activo y la comprensión de conceptos matemáticos y gráficos.
- Beneficios: Facilitan la creación directa y la exploración táctica de gráficos, lo que fomenta el aprendizaje interactivo.
Ambos sistemas se ven combinados en Fig. 31.4: a la izquierda los gráficos táctiles impresos en relieve, a la derecha los tableros con pines y bandas elásticas.
Impresión 3D para Gráficos Táctiles
Con la llegada de las impresoras 3D, es posible crear gráficos táctiles con relieves pronunciados y personalizados. Esto permite a los usuarios generar gráficos táctiles en casa con mayor precisión y accesibilidad. Los relieves más pronunciados mejoran la capacidad de lectura táctil y ofrecen la posibilidad de representar datos de manera más detallada y clara.
Algunos ejemplos de visualizaciones impresas en 3D Fig. 31.5 muestran cómo el relieve significativo permite a usuarios ciegos seguir los contornos con los dedos.

La investigación ha mostrado que los gráficos extruidos en 3D, que permiten a los usuarios ciegos seguir los contornos de los objetos, son más efectivos que los gráficos tradicionales en 2D.
Sistemas de Gráficos Tangibles Interactivos
Tangible Graph Builder: Inspirado en el tablero de gráficos, este sistema combina objetos tangibles con tecnología de seguimiento y sonificación. Permite a los estudiantes ciegos construir gráficos en 3D, como gráficos de barras y de líneas, con retroalimentación auditiva para mejorar la comprensión.
Linespace: Es un sistema interactivo que permite a los usuarios ciegos explorar gráficos táctiles en tiempo real. Utiliza una impresora 3D equipada con un raspador mecánico que permite generar y borrar gráficos táctiles bajo demanda, mediante gestos y comandos de voz.
✋ El salto: del relieve fijo al gráfico que responde. Un gráfico táctil impreso es un objeto cerrado — lo que salió, salió. Tangible Graph Builder y Linespace rompen esa rigidez: la superficie táctil escucha, se regenera y dialoga con el usuario. Es el mismo paso de la vista general a la interacción, ahora bajo los dedos.
Estos dos sistemas se muestran lado a lado en Fig. 31.6: Tangible Graph Builder con sus bloques físicos sobre una superficie con sensores, y Linespace con la impresora 3D y el raspador mecánico que permite generar y borrar gráficos bajo demanda.
Tangible Reels: Sistema que permite a los usuarios ciegos construir y explorar redes físicas de líneas sobre una superficie plana, usado para representar jerarquías o gráficos de barras.
Oportunidades Futuras
Aunque la fisicalización de datos ha avanzado significativamente, todavía hay áreas de oportunidad para investigar y desarrollar. Actualmente, muchos sistemas de fisicalización accesibles se basan en adaptaciones de gráficos en 2D, pero existen posibilidades de crear representaciones más ricas que aprovechen al máximo las capacidades hápticas de los usuarios ciegos.
- Nuevas Dimensiones Físicas: Representaciones que utilicen texturas, temperatura o suavidad podrían abrir nuevas vías para que las personas con discapacidades visuales exploren datos de forma más completa.
- Interacción Más Profunda: Incorporar sistemas que permitan una mayor interactividad y personalización podría mejorar la experiencia de exploración de datos y fomentar una comprensión más profunda.
Fisicalización estética: pantallas ambientales, arte informativo y esculturas de datos

La fisicalización no solo informa, también puede emocionar. Cuando los datos se vuelven escultura o ambiente, algo cambia en cómo los sentimos.
Físicalización para disfrutar experiencias y generar significado
La físicalización de datos, cuando se aborda desde la disciplina de la visualización de la información, suele tener propósitos mayormente pragmáticos. Sin embargo, conceptualizaciones más amplias, como la visualización estética, artística o casual, han reconocido que también puede ser aprovechada para expresar y no solo comunicar puntos de vista específicos relacionados con los datos.
De lo pragmático a lo estético
🎨 La belleza y el juego no son adornos: son motivos legítimos. La visualización clásica se mide por rendimiento —rápida, exacta, clara—. Pero un dato que además divierte o emociona invita a volver, a explorar, a quedarse. La fisicalización estética persigue justamente eso: que el dato no sólo se entienda, sino que se disfrute.
Dentro del campo de la visualización de información, la representación de datos se orienta mayoritariamente hacia objetivos prácticos. Sin embargo, enfoques más amplios, como la visualización estética, artística o casual, destacan cómo estas representaciones también pueden emplearse para expresar, en lugar de simplemente comunicar, puntos de vista particulares relacionados con los datos. Estas visualizaciones, al llegar a una audiencia más amplia y menos experta en alfabetización visual, han motivado la investigación sobre cómo características hedónicas, como la "diversión" o la "belleza", pueden complementar los criterios pragmáticos tradicionales de rendimiento en visualización.
El Modelo de Motivación Promotor-Inhibidor (PIMM) proporciona un marco valioso para analizar los factores que influyen en el uso de visualizaciones, y se vuelve especialmente pertinente al considerar la físicalización de datos. Este enfoque transforma la representación de información en experiencias sensoriales y físicas, lo que estimula una interacción más rica y envolvente con los datos.
En este contexto, la físicalización actúa como un motivador promotor clave. La posibilidad de interactuar físicamente con las representaciones de datos permite a los usuarios explorar, jugar y experimentar con la información de maneras que las visualizaciones tradicionales no pueden ofrecer. Esta interactividad no solo despierta la curiosidad, sino que también fomenta un sentido de conexión y compromiso con el contenido, lo que resulta en una experiencia de aprendizaje más efectiva.
Las motivaciones promotoras, como la diversión y la estética, se ven intensificadas por la naturaleza tangible de las físicalizaciones. Cuando los usuarios pueden manipular y explorar físicamente los datos, su interés y atención se incrementan, lo que a su vez facilita una comprensión más profunda y duradera de la información. Esto se traduce en una mayor frecuencia y duración de la interacción, ya que las personas se sienten más atraídas a regresar a estas experiencias que enriquecen su comprensión de los datos.
Además, las representaciones memorables que surgen de la físicalización no solo cautivan a los usuarios, sino que también mejoran la retención y el aprendizaje a largo plazo. Este tipo de interacción no solo transforma la forma en que se perciben los datos, sino que también abre nuevas oportunidades para comunicar información de manera efectiva y accesible.
Pantallas ambientales y arte informativo
El ámbito de las pantallas ambientales ha sido pionero en la creación de algunas de las primeras físicas de datos habilitadas por computadora. Estos sistemas experimentan con la traducción de valores de datos en aspectos ambientales percibidos de manera sutil, como la luz, el sonido o el movimiento, que pueden ser procesados en segundo plano por los sentidos humanos.
🎨 Información que percibes sin mirarla. Una pantalla ambiental no reclama tu atención: traduce el dato en luz, sonido o movimiento que el cuerpo registra de fondo, mientras haces otra cosa. No todo dato necesita un dashboard — algunos viven mejor como el clima del espacio.
Dos ejemplos clásicos de pantallas ambientales (Fig. 32.1) ilustran este enfoque: la instalación Pinwheels presenta información a través de sutiles cambios en luz, sonido y movimiento, permitiendo a los usuarios percibir datos sin centrarse directamente en ellos; mientras que el BusMobile indica la proximidad de autobuses a una parada mediante la altura de los números que representan a cada vehículo, ofreciendo una forma intuitiva de acceder a esta información en un entorno público.

El arte informativo, por su parte, integra datos en formas artísticas. Un ejemplo es la instalación Infotropism (Fig. 32.2), donde una planta robótica se inclina hacia una lámpara cuya iluminación depende del uso de un contenedor de reciclaje, ilustrando el impacto del comportamiento ecológico a través del crecimiento de la planta. Este enfoque estético y sutil logra comunicar información sobre el medio ambiente de una manera visualmente agradable y simbólica.

Expresión artística
La visualización de datos también es empleada fuera de los entornos científicos, en campos como el diseño gráfico, la arquitectura y el arte interactivo. Estas representaciones suelen ser más abstractas, con el objetivo de provocar una reflexión en lugar de transmitir información clara y precisa.
🎨 Cuando la forma misma es el mensaje. En una escultura de datos el significado no vive en una leyenda ni en un eje: vive en el objeto — en su peso, su tamaño, su resistencia a ser manipulado. La forma deja de mostrar el dato y pasa a argumentarlo, a veces con una carga política que una pantalla no podría transmitir.
Por ejemplo, el concepto de escultura de datos combina cualidades funcionales y artísticas para promover una mayor comprensión de fenómenos sociales o científicos. Un ejemplo icónico es el Data Table (Fig. 32.3), una mesa cuya superficie refleja estadísticas de la riqueza global: si se invierte, muestra una distribución equitativa, pero su peso real dificulta esta acción, representando las barreras para cambiar el sistema económico actual.

Tecnologías para la físicalización
Históricamente, las físicalizaciones de datos se realizaban de manera manual, lo que requería considerable tiempo y esfuerzo. No obstante, los avances tecnológicos han facilitado la creación de estas representaciones, permitiendo incorporar dinamismo y computación en ellas. Este desarrollo es paralelo a la evolución de las visualizaciones tradicionales, que también dependían de un trabajo manual intensivo.
Fabricación Digital: Las tecnologías de fabricación digital, como la impresión 3D y el corte láser (Fig. 32.4), han acelerado drásticamente el proceso de creación de físicalizaciones estáticas. Estas herramientas han sido adoptadas por científicos para visualizar datos tridimensionales y se utilizan cada vez más para generar gráficos accesibles y dar forma física a datos personales. La disponibilidad generalizada de estas tecnologías ha contribuido a un aumento significativo en la creación de esculturas de datos en la última década.

Agilizar el Diseño: La creación de archivos de diseño, esenciales para la fabricación digital, puede ser un proceso complicado. Es por esto que la investigación en interacción humano-computadora se está enfocando en simplificar esta tarea mediante herramientas que permiten leer datos y proponer físicalizaciones parametrizables. Aunque existen sistemas como MakerVis (Fig. 32.5), que soportan la creación de gráficos en 3D y son compatibles con diversas tecnologías de fabricación, todavía no hay una herramienta de propósito general que permita a los usuarios físicalizar cualquier conjunto de datos, lo que deja un amplio espacio para la investigación futura.
Tecnologías de Actuación: Las tecnologías de actuación son fundamentales para que las físicalizaciones sean tan interactivas y receptivas como las visualizaciones en pantalla. La subcomunidad de interacción humano-computadora que trabaja en interfaces tangibles se centra en proponer tecnologías que permiten el control computacional de las geometrías físicas y las propiedades materiales, como por ejemplo EMERGE y inForm (Fig. 32.6), dos interfaces transformables basadas en matrices de pines actuados que reconstruyen barras y formas 3D dinámicas.

Un ejemplo accesible de estas tecnologías es LEGO Technics Fig. 32.7. Aunque presenta limitaciones, permite a las personas interactuar físicamente con estructuras sencillas que representan datos mediante bloques de plástico, motores y servos. Esto fomenta una experiencia lúdica que invita a explorar y comprender mejor la información a través de la manipulación directa.
| Nota sobre Técnicas de Prototipado Rápido para Físicalizaciones Para desarrollar nuestras físicalizaciones de datos, emplearemos técnicas sencillas de prototipado rápido (ver clase 18 y 19) que nos permitan experimentar y materializar ideas de manera eficiente y accesible. Estas técnicas incluyen: * Papel y cartón: Materiales versátiles que nos permiten crear maquetas y estructuras básicas rápidamente, facilitando la visualización de conceptos. * Cinta adhesiva: Herramienta esencial para unir y asegurar elementos en nuestras construcciones, lo que ayuda a mantener la integridad estructural de los prototipos. * Impresoras 2D: Utilizaremos impresoras para producir gráficos, etiquetas y otros elementos visuales que cubrirán partes de nuestras estructuras en 3D, mejorando la presentación y comprensión de la información. * Smartphones y computadoras: Estos dispositivos servirán como herramientas para interactuar con las físicalizaciones, a través de sus sensores y actuadores, como parlantes, cámaras y acelerómetros, permitiendo la incorporación de datos digitales y experiencias interactivas. * LEGO Technics: Este sistema nos permite construir estructuras físicas que incorporan componentes reactivos, como motores y servos, lo que añade una dimensión interactiva y lúdica a nuestras representaciones de datos. A través de estas técnicas de prototipado rápido, buscaremos crear físicalizaciones que no solo sean efectivas en la comunicación de información, sino que también inviten a la exploración y comprensión activa por parte de los usuarios. |
Ejemplos de fisicalización de información
Más allá de los ejemplos canónicos vistos en esta cápsula, vale la pena conocer el catálogo de referencia de la comunidad: la página Data Physicalization (dataphys.org) mantiene un repositorio extenso de proyectos de visualización tangible, desde piezas históricas hasta instalaciones contemporáneas. La galería principal permite filtrar por técnica, material y propósito, y es una fuente recurrente de inspiración tanto para proyectos pedagógicos como para esculturas de datos serias. Conviene tenerla siempre cerca cuando estés diseñando una fisicalización propia: lo más probable es que alguien ya haya explorado una variante de tu idea y haya documentado qué funcionó y qué no.
T5. Protobject Framework: tu celular es el sensor, tu computador la pantalla
Cada página HTML es un dispositivo. Conectarlos sin instalar nada
Tu celular tiene más sensores que un laboratorio de los 90. Tu computador, más pantalla que un cine de los 70. Conectarlos para crear visualizaciones físicas es cuestión de unas pocas líneas.
¿Qué es Protobject Framework?
Un framework que convierte cada página HTML en un dispositivo independiente y los hace comunicar entre sí en tiempo real. Sin servidores propios, sin hardware adicional. Tu computador es la pantalla, tu celular el sensor, y ambos hablan vía WebSocket.
Tu celular es el sensor. Tu computador es la pantalla. Protobject los conecta.
Estructura del proyecto
Un proyecto Protobject es una carpeta con varios .html. Cada uno
representa un dispositivo:
index.html→ la visualización (corre en el computador)button.html,hand.html,face.html, … → sensores / controles (corren en celulares u otras ventanas)
No solo smartphones — también cámaras, sensores Arduino, otros computadores.
Boilerplate de cada página
Cada .html empieza con dos <script>:
<!DOCTYPE html>
<html>
<head>
<script src="https://app.protobject.com/framework/p.js"></script>
<script src="config.js"></script>
</head>
<body>
<script>
// tu código acá
</script>
</body>
</html>
config.js declara los dispositivos
Todas las páginas del proyecto cargan el mismo config.js, que declara
las páginas que componen el prototipo:
// config.js — compartido por todas las páginas
Protobject.initialize([
{ name: "Visualización", page: "index.html" },
{ name: "Botón", page: "button.html" }
]);
index.html es la página principal (la pantalla del computador); las demás
son dispositivos secundarios que se conectan al escanear un QR (Fig. 33.1).

Comunicación entre páginas
// Enviar a una página específica
Protobject.Core.send({ encendido: true }).to("index.html");
// Enviar a todas las demás
Protobject.Core.send({ temperatura: 25 });
// Recibir
Protobject.Core.onReceived(mensaje => {
console.log("Llegó:", mensaje);
});
Los mensajes son JSON — cualquier objeto serializable.
Versión didáctica: botón → lámpara
El "hola mundo" de Protobject. Dos páginas, una visualización
(index.html) y un control en el celular (button.html).
button.html (celular):
const btn = new Protobject.Button({ label: "ON / OFF" });
let estado = false;
btn.onPress(() => {
estado = !estado;
Protobject.Core.send(estado).to("index.html");
});
index.html (computador):
const lamp = new Protobject.Lamp({ width: '100%', height: '80vh' });
Protobject.Core.onReceived(encendido => {
lamp.setColor(encendido ? { r:0, g:255, b:100 } : { r:0, g:0, b:0 });
});
💻 Abrir el demo lamp · necesita un celular emparejado via QR de Protobject
Sensores del celular
Para hacer cosas más interesantes que un botón, usa los sensores del smartphone:
| Sensor | Objeto Protobject | Datos |
|---|---|---|
| Acelerómetro | Protobject.Acceleration |
x, y, z (m/s²) |
| Giroscopio | Protobject.Orientation |
alpha, beta, gamma (°) |
| Inclinación | Protobject.Inclination |
tilt 3D filtrado |
// Reaccionar al ángulo del celular
Protobject.Orientation.onChange(angle => {
// angle.alpha = brújula (0-360)
// angle.beta = inclinación adelante/atrás (-180 a 180)
// angle.gamma = inclinación izquierda/derecha (-90 a 90)
Protobject.Core.send({ angulo: angle.gamma }).to("index.html");
});
Versión esperada — calefacción / puerta abierta
El celular es la puerta de una casa. Inclinarlo simula abrirla. La visualización en pantalla muestra:
- Plotly de la temperatura interior (curva exponencial decreciente)
- Cuanto más se abre la puerta, más rápido baja la temperatura
- Pasado cierto umbral suena un MP3 de fondo y aparece el mensaje "Cerrá la puerta"
// door.html (celular — la "puerta")
Protobject.Orientation.onChange(angle => {
Protobject.Core.send({ apertura: Math.abs(angle.gamma) }).to("index.html");
});
// index.html (computador — la "casa")
let temperatura = 20;
let aperturaActual = 0;
Protobject.Core.onReceived(({ apertura }) => {
aperturaActual = apertura;
});
setInterval(() => {
// pérdida de calor proporcional a la apertura
temperatura -= aperturaActual * 0.05;
actualizarPlotly(temperatura);
if (aperturaActual > 4) reproducirAlerta();
}, 100);
💻 Abrir el demo heater · necesita un celular emparejado (la inclinación del celular = puerta abriéndose)
🎯 Proyecto · el gesto de inclinar el celular encarna la metáfora de abrir la puerta — sensor físico + dato + sonido construyen una narrativa coherente. Esto es nivel de proyecto. (Ver el funcionamiento en el video del overview, arriba.)
Todos los proyectos del curso usan Protobject
Cada proyecto del curso construye sobre las bases de esta cápsula:
config.js declara los dispositivos, Protobject.Core.send/onReceived
los conecta, y al menos un sensor del celular o de la cámara forma parte
del prototipo. Esto es la columna vertebral que sostiene los demos de
T6 (sensores avanzados) y T7 (Arduino).
Algunos ejemplos rápidos — el detalle visual y el código completo están en T6 / T7:
| Proyecto | Sensor Protobject | Cápsula donde lo vemos |
|---|---|---|
| Casita que tiembla | acelerómetro celular | T5 base → completo en T7 |
| Electricidad por región | HandSensor (mano) |
T6 |
| Migración de gaviota | HandSensor (gesto) |
T6 |
| Mundiales de fútbol | Aruco (marcadores físicos) |
T6 |
| Cereales | Acceleration (agitar el paquete) |
T6 |
| Medallistas 100m | Arduino (servo continuo) |
T7 |
| Gasto militar mundial | Arduino (servo "lanzamisil") |
T7 |
| Montañas rusas | sin sensor, solo audio | T4 |
| Lluvia / viento | sin sensor, solo audio | T4 |
El patrón es siempre el mismo: una
index.htmlcon la visualización + una o varias páginas secundarias (hand.html,arduino.html,aruco.html,motionsensor.js, …) que actúan como sensores. La cápsula T6 entra en detalle.
Más ejemplos del framework Protobject
El framework tiene también una galería de prototipos ubicomp (no data-viz): alarmas con sensor de movimiento, alertas de ruido, correctores de postura, iluminación inteligente, cerraduras con código. Sirven como inspiración para entender la amplitud de cosas que se pueden hacer con la misma base que vimos acá.
→ Ver la galería ubicomp del framework
Lo que viene después
En T6 subimos un escalón: usamos la cámara web con MediaPipe para detectar manos, cuerpo y cara. El usuario interactúa con el cuerpo entero, sin tocar nada.
En T7 cerramos con Arduino + LEGO Technic: el dato sale de la pantalla y mueve un servo físico.
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
T6. Sensores físicos con MediaPipe: ArUco, mano, cuerpo y cara
MediaPipe en el navegador: tu cuerpo es la interfaz
Tu mano apunta, tu cara mira, tu cuerpo se mueve: todo eso son datos que el navegador puede leer en tiempo real. La interfaz dejó de ser solo un mouse hace rato.
Más allá del botón: cuerpo y objetos como sensor
Protobject incluye modelos de visión computacional (MediaPipe de Google) que corren directamente en el navegador, sin servidores ni instalaciones. Tu cámara web se convierte en un sensor de alta precisión.
Privacidad: todo el procesamiento es local. La cámara nunca envía video a servidores externos.
ArUco: objetos físicos como input
Imprimes marcadores ArUco con un generador online (Fig. 34.1), los pegas a objetos físicos (porotos, té, atún, ...) y la cámara los reconoce. Cambiando el orden vertical de los objetos, se reordena el orden de las series del gráfico.

// order.html (cámara)
Protobject.Aruco.onDetected(markers => {
// markers = [{ id: 1, x, y }, { id: 100, x, y }, ...]
const orderById = markers.sort((a, b) => a.y - b.y).map(m => m.id);
Protobject.Core.send({ order: orderById }).to("index.html");
});
💻 Abrir el demo ordering · necesita cámara + marcadores ArUco impresos (genéralos en chev.me/arucogen)
📚 Didáctica · muestra la mecánica ArUco → orden de series, sin storytelling. (El video del overview de T5, arriba, los muestra en acción.)
Mano: Protobject.HandSensor (MediaPipe Hand)
Detecta 21 landmarks por mano y categorías de gestos predefinidos
(Thumb_Up, Thumb_Down, Open_Palm, Closed_Fist, ...).
Demo finger — el dedo señala el mapa
El landmark 8 es la punta del dedo índice. Su posición sobre un mapa
SVG detecta sobre qué país está apuntando, y Protobject.TextToSpeech
narra las exportaciones de fruta de ese país.
// hand.html (cámara)
Protobject.HandSensor.onChange(hand => {
const tip = hand.landmarks[8]; // {x: 0-1, y: 0-1}
Protobject.Core.send({ x: tip.x, y: tip.y }).to("index.html");
});
// index.html
Protobject.Core.onReceived(({ x, y }) => {
const country = countryAt(x, y);
if (country !== currentCountry) {
currentCountry = country;
Protobject.TextToSpeech.play({
lang: "es-CL",
text: `${country} exportó ${exports[country]} millones`
});
}
});
💻 Abrir el demo finger · necesita cámara web (MediaPipe HandSensor detecta la punta del índice)
📚 Didáctica · concepto claro pero diseño visual mínimo.
Cuerpo: Protobject.BodySensor (MediaPipe Pose)
Detecta 33 puntos del esqueleto (nariz, hombros, codos, caderas, ...). Los más útiles:
- landmarks 11 y 12 → hombros (distancia entre ellos = zoom)
- landmark 0 → nariz (posición horizontal = pan)
Demo bodyzoom — el cuerpo controla el gráfico
Acercarse a la cámara → la distancia entre hombros aumenta → zoom in en la cotización de Apple. Moverse a la izquierda o derecha → el nose corre horizontalmente → pan sobre la línea temporal.
// body.html (cámara)
Protobject.BodySensor.onChange(landmarks => {
const dx = landmarks[12].x - landmarks[11].x; // distancia hombros
const zoom = mapToRange(dx, 0.1, 0.4, 1, 10);
const pan = landmarks[0].x; // nariz horizontal
Protobject.Core.send({ zoom, pan }).to("index.html");
});
Filtro de Kalman. Las landmarks de MediaPipe tiemblan frame a frame. El demo aplica un filtro de Kalman simple para suavizar el valor antes de enviarlo, evitando que el gráfico vibre.
💻 Abrir el demo bodyzoom · necesita cámara web (MediaPipe Pose detecta hombros y nariz)
📚 Didáctica · muestra MediaPipe Pose + Kalman + Plotly. Pero el zoom con el cuerpo no aporta nada que el zoom con mouse no haga mejor: la interacción es impresionante, no significativa. Útil como demo técnica, no como modelo de proyecto.
Cara: Protobject.FaceSensor (MediaPipe Face)
Devuelve blendshapes (categorías como sonrisa, ceño fruncido, ojos cerrados) y permite contar caras frente a la cámara.
Demo bcprediction — sonrisa / pulgar / inclinación
Tres dispositivos en paralelo cambian la predicción de Bitcoin:
- sonrisa detectada → "Optimista"
- ceño fruncido → "Pesimista"
- pulgar arriba/abajo (HandSensor) → ídem
- inclinar el celular (Inclination) → ídem
Los tres caminos llegan al mismo index.html que actualiza la predicción.
Protobject.FaceSensor.onChange(face => {
const smile = face.blendshapes.mouthSmileLeft + face.blendshapes.mouthSmileRight;
const frown = face.blendshapes.browDownLeft + face.blendshapes.browDownRight;
if (smile > 0.5) Protobject.Core.send("Optimista");
else if (frown > 0.5)Protobject.Core.send("Pesimista");
else Protobject.Core.send("Neutral");
});
💻 Abrir el demo bcprediction · necesita cámara web + celular emparejado (FaceSensor + HandSensor + Inclination)
📚 Didáctica · sirve como provocación creativa pero sonreír al gráfico no cambia el dato — la interacción no comunica conocimiento sobre Bitcoin, solo demuestra la integración multi-sensor. Útil para aprender la técnica.
Demo consumption — el contexto cambia los datos
Cuántas caras hay frente a la cámara → tantos perfiles de consumo eléctrico se resaltan en el gráfico polar. La InfoVis se adapta al número de personas que la están mirando.
Protobject.FaceSensor.onChange(face => {
const n = face.faceLandmarks.length; // cuántas caras detectadas
Protobject.Core.send({ personas: n }).to("index.html");
});
💻 Abrir el demo consumption · necesita cámara web (cuenta caras frente al lente)
🎯 Proyecto · adaptación contextual significativa: el dato mostrado cambia en función de quién lo está mirando. La interacción aporta — el sensor lee el contexto colectivo, no es un control.
Cuándo el sensor avanzado vale la pena
Mirando los demos didácticos arriba (zoom con cuerpo, sonrisa para Bitcoin) queda claro un patrón: la cámara y MediaPipe son tan novedosos que es fácil usarlos sin pensar. La pregunta importante no es "¿puedo detectar sonrisas?" sino "¿la sonrisa cuenta algo del dato?".
Antes de añadir un sensor avanzado al proyecto preguntate:
- ¿El sensor lee el contexto (cuántos están mirando, dónde apuntan, en qué orden ponen los objetos) — o es un control disfrazado de sensor?
- ¿Hay una alternativa con mouse/teclado igual de buena? Si sí, el sensor probablemente es decoración.
- ¿La interacción emociona, contextualiza o hace accesible? (los tres contextos que ya vimos en T4 para sonificación).
Si las tres respuestas son sí, adelante.
Proyectos del curso — cuándo el sensor sí aporta
Estos son demos hechos por estudiantes en años anteriores donde el sensor funciona por una razón. Cada uno reutiliza una visualización que ya vimos en T1 / T2 y le añade un sensor físico que encaja con la metáfora del dato.
El video es lo importante — los prototipos físicos no se pueden ejecutar en el sitio (necesitan cámara web, marcadores ArUco impresos, celular emparejado, …). El código fuente está disponible como recurso secundario para inspirarte en tu proyecto.
Electricidad por región (Chile)
La mapa estático de T2 (consumo per cápita por región) ahora reacciona a la mano: acercar el índice al mapa resalta la región bajo el dedo con su consumo. Acá el gesto de "señalar" mapea a la metáfora de "esa región" — se siente natural, no decorativo.
Migración de gaviota
La trayectoria estática de T2 y la sonificación de T4 se ejecutan ahora a partir de un gesto de la mano: el "soltar la gaviota" dispara la animación del recorrido. El gesto es ritual, no botón.
💻 Código fuente · sensor:
Protobject.HandSensor + Tone.js · viz base: T2 estático · sonificación: T4Mundiales de fútbol
El mapa coroplético de T2 (países anfitriones) navegable con marcadores ArUco físicos: cada marcador representa un Mundial. Cambiar de torneo es mover un objeto, no hacer click.
Cereales
El celular se transforma en contador físico dentro del paquete: el sensor de movimiento (acelerómetro) detecta cuándo se agita. El acto de agitar el paquete mapea a "estimar cuánto cereal queda".
📦 sensor:
Protobject.Acceleration (celular dentro del paquete)Tabla resumen — cuándo usar cada sensor
| Sensor | Para… | Latencia típica |
|---|---|---|
Protobject.Aruco |
objetos físicos discretos | ~30 fps |
Protobject.HandSensor |
gestos finos, señalar | ~30 fps |
Protobject.BodySensor |
postura, distancia, gestos amplios | ~25 fps |
Protobject.FaceSensor |
expresión, conteo de personas | ~30 fps |
Protobject.Acceleration |
movimiento del celular | < 10 ms |
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaNº de personas frente a la cámara cambia el perfil de consumo🎯 EsperadaElectricidad por región — la mano apunta el mapa de Chile (estudiante)🎯 EsperadaMigración de gaviota — gesto de la mano dispara el viaje (estudiante)🎯 EsperadaMundiales de fútbol — ArUco navega entre torneos (estudiante)
T7. Arduino + LEGO Technic: actuadores físicos y capstone de la casita que tiembla
Servos, motores y la 'casita que tiembla': todo el curso en un demo
La información que se siente. Servos que vibran, motores que giran, piezas LEGO que tiemblan al ritmo de un terremoto real. El último paso del curso: hacer que los datos tomen forma física.
Del dato al objeto: actuadores físicos
Los sensores del celular son potentes (T5–T6), pero para objetos que se mueven, vibran o cambian de forma necesitamos actuadores físicos. LEGO Technic + Arduino es el camino que el curso usa.
LEGO Technic: mecanismos sin soldar
LEGO Technic permite construir mecanismos complejos (engranajes, palancas, poleas) con piezas que encajan con precisión. No requiere herramientas ni soldadura.
Por qué para InfoVis:
- modificar y reiterar es gratis (desmontar y rearmar)
- piezas estandarizadas → prototipado rápido
- compatibles con servos hobby
Recursos para aprender: - Brick Experiment Channel — experimentos con mecanismos LEGO
Servos: angulares vs continuos
Hay dos tipos de servo, y conviene distinguirlos antes de ensamblar (Fig. 35.1).

- Servo angular (M, 180°) — ideal para indicadores tipo aguja, valor que se mapea a posición.
- Servo continuo (C) — gira sin tope, ideal para hacer vibrar un objeto, empujarlo, o moverlo a velocidad variable.
Conexión a Arduino
Tres cables por servo: Señal · 5V · Tierra (Fig. 35.2).
Regla del curso: usar siempre pin 5 o pin 6 para servos.
Son los dos pines que asume todo el código de ejemplo del curso (Fig. 35.3).
Alimentación: el Arduino se conecta por USB-C al PC, o por adaptador a un smartphone.
API Protobject.Arduino
Protobject incluye un bridge Web Serial que conecta Arduino directamente desde el navegador (Chrome / Edge), sin instalar drivers. Cargas un sketch genérico una vez en el Arduino, y desde JS controlas los pines:
await Protobject.Arduino.start(); // pide permiso Web Serial
Protobject.Arduino.servoWrite({ pin: 5, value: 90 }); // angular 0-180°
Protobject.Arduino.contServoWrite({ pin: 5, value: 1500 }); // continuo (-1500..1500)
Versión didáctica: knob → servo continuo
El "hola mundo" de Arduino con Protobject. Dos páginas:
index.html (la perilla en pantalla):
const perilla = new Protobject.Knob({ min: -1500, max: 1500 });
perilla.onChange(value => {
Protobject.Core.send({ speed: value }).to("arduino.html");
});
arduino.html (la pestaña con permiso Web Serial):
await Protobject.Arduino.start();
Protobject.Core.onReceived(data => {
Protobject.Arduino.contServoWrite({ pin: 5, value: data.speed });
});
💻 Abrir el demo knob-servo · necesita Arduino + servo continuo conectado por USB (Web Serial)
📚 Didáctica · solo muestra cómo conectar Arduino con Protobject. Sin contexto ni datos.
Versión esperada — la casita que tiembla (capstone)
Este demo integra todo lo del curso técnico, en orden:
| Cápsula | Aporta | Cómo aparece |
|---|---|---|
| T1 | gráfico Plotly base | gráfico magnitud × fecha |
| T2 | Plotly Geo + SVG | mapa scattergeo de Chile + SVG de contexto |
| T3 | interacción | hover y click sobre cada terremoto |
| T4 | sonificación | tres MP3 mezclados según magnitud |
| T5 | Protobject + smartphone | acelerómetro del celular como sensor |
| T6 | Kalman / sensor avanzado | suaviza la aceleración detectada |
| T7 | Arduino + servo | servo continuo vibra una casita LEGO |
Así se ve el prototipo físico terminado (Fig. 35.4).

mapa.on('plotly_click', e => {
const m = e.points[0].marker.color; // magnitud
// 1. sonido (T4)
new Audio(audioFor(m)).play();
// 2. servo: velocidad ~ magnitud (T7)
const speed = Math.round(scale(m, 5, 9, 600, 1500));
Protobject.Core.send({ speed }).to("arduino.html");
// 3. cortar después de 4 segundos
setTimeout(() => {
Protobject.Core.send({ speed: 0 }).to("arduino.html");
}, 4000);
});
🎯 Proyecto · capstone integral. La vibración física recrea la sensación corporal del terremoto que el dato describe — el actuador no decora, encarna.
💻 Código fuente del capstone · necesita Arduino + servo continuo + casita LEGO para correr en vivo
Proyectos del curso — actuadores con sentido
Seis demos de estudiantes donde el actuador funciona por una razón. Cada uno reutiliza una visualización que ya vimos en cápsulas anteriores y le añade movimiento físico —o vibración— que encarna el dato.
El video es lo importante — los proyectos físicos no se pueden ejecutar en el sitio (necesitan Arduino, servo y montaje LEGO). El código fuente se mantiene como recurso secundario.
Medallistas 100m olímpicos
El bar chart estático de T1 (medallistas 100m) ahora se cruza con un servo: pasas el mouse sobre cada ganador y el servo gira a una velocidad proporcional a su tiempo de carrera; al mismo tiempo suena un loop de pasos corriendo. La velocidad mecánica encarna la velocidad humana.
Gasto militar mundial
El mapa coroplético de T2 (gasto militar como % del PIB) y el slider por año que vimos en T3 se completan ahora con un servo: click en un país y el servo hace el gesto de "lanzar un misil" — sube, dispara, vuelve a la posición inicial. El gasto militar literal se convierte en gesto literal. Provocador y claro.
Intensidad del viento
El gráfico estático de T1 (intensidad del viento en la Quinta Región) se completa con dos servos a la vez: al pasar el mouse sobre una medición, un servo angular gira como veleta para apuntar la dirección del viento, mientras un servo continuo gira a una velocidad proporcional a su intensidad. El objeto se vuelve un anemómetro físico — de dónde sopla y con cuánta fuerza, a la vez.
Montañas rusas más rápidas
El mapa de T2 (las montañas rusas más rápidas del mundo) se cruza con un servo continuo: al hacer click en una montaña rusa, el servo acelera hasta una velocidad proporcional a la del juego — arranca suave y sube, como el carro al soltar el freno. La velocidad mecánica encarna la velocidad del vértigo.
Lluvias en Chile
El mapa de lluvias por región de Chile —cuya versión sonora vimos en T4— suma un servo angular que funciona como aguja de un medidor: al recorrer una estación, el servo apunta a una posición proporcional a la intensidad de la lluvia. El dato meteorológico se vuelve gesto de instrumento.
Autos más rápidos
El gráfico estático de T1 (los autos más rápidos del mundo) suma dos canales físicos: al pasar el mouse sobre un auto, el celular vibra con una frecuencia atada a su velocidad; al hacer click, un servo continuo hace avanzar un auto de LEGO sobre la mesa — acelera, frena y se detiene. La cifra se siente en la mano y se ve correr.
💻 Código fuente · actuador:
Protobject.Arduino.contServoWrite + Protobject.Haptic · viz base: T1 estáticoOtros actuadores
| Actuador | Controla | Uso típico en InfoVis |
|---|---|---|
| Servo angular | posición 0-180° | aguja indicadora |
| Servo continuo | velocidad/dirección | barra que sube, vibrador |
| LED RGB | color | estado categórico |
| LED strip (WS2812) | color × N LEDs | escala visual |
| Buzzer | tono | alertas sonoras |
| Motor paso a paso | posición precisa | mecanismos finos |
Diseño de la fisicalización
No es solo "conectar hardware". El objeto físico debe:
- Codificar datos claramente — movimiento / color / forma → variable
- Ser legible sin instrucciones — si necesita explicación, rediseñá
- Complementar lo digital — no reemplazar la pantalla, dialogar con ella
- Ser reproducible — materiales accesibles, proceso documentado
Versiones didácticassolo muestran el mecanismo. NO son nivel de proyecto.
Versiones esperadascon narrativa, diseño y mensaje claro. Este es el nivel de proyecto.
🎯 EsperadaCapstone — la casita que tiembla (mapa + audio + Arduino)🎯 EsperadaMedallistas 100m olimpiadas — servo gira a la velocidad del corredor (estudiante)🎯 EsperadaGasto militar mundial — el servo "lanza" un misil al hacer click (estudiante)🎯 EsperadaIntensidad del viento — dos servos marcan dirección y fuerza del viento (estudiante)🎯 EsperadaMontañas rusas — un servo continuo gira a la velocidad de la montaña rusa (estudiante)🎯 EsperadaLluvias en Chile — un servo-aguja marca la intensidad de la lluvia (estudiante)🎯 EsperadaAutos más rápidos — un auto LEGO acelera y el celular vibra (estudiante)
Bibliografía Completa
-
A. Dix (2013). Introduction to Information Visualisation. Information Retrieval Meets Information Visualization, LNCS 7757, 2013, pp 1-27
-
Munzner, T. (2014). Visualization analysis and design. CRC press.
-
Spence, R. (2001). Information visualization (Vol. 1). New York: Addison-Wesley.
-
Cabitza, F. (2020). Introduzione alla Visualizzazione dei Dati, in Batini, C. et al., La scienza dei dati.
-
Ware, C. (2019). Information visualization: perception for design. Morgan Kaufmann.
-
E.R. Tufte (2001). The visual display of quantitative information. Cheshire, CT: Graphics press.
-
A. Cairo (2016). The truthful art: data, charts, and maps for communication. New Riders.
-
Bellino, A., & Bascuñán, D. (2020). Design and evaluation of writebetter: A corpus-based writing assistant. IEEE Access, 8, 70216-70233.
-
Harris, J. J., Schwarzkopf, D. S., Song, C., Bahrami, B., & Rees, G. (2011). Contextual illusions reveal the limit of unconscious visual processing. Psychological science, 22(3), 399-405.
-
Knaflic, C. N. (2015). Storytelling with data: A data visualization guide for business professionals. John Wiley & Sons.
-
Yau, N. (2013). Data points: Visualization that means something. John Wiley & Sons.
-
Caveats — A collection of dataviz caveats by data-to-viz.com
-
Tufte, E. R., & Graves-Morris, P. R. (1983). The visual display of quantitative information (Vol. 2, No. 9). Cheshire, CT: Graphics press.
-
Krzywinski, M., Savig, E. Multidimensional data. Nat Methods 10, 595 (2013).
-
Shneiderman, B. (2003). The eyes have it: A task by data type taxonomy for information visualizations. In The craft of information visualization (pp. 364-371). Morgan Kaufmann.
-
Zuk, T., Schlesier, L., Neumann, P., Hancock, M. S., & Carpendale, S. (2006, May). Heuristics for information visualization evaluation. In Proceedings of the 2006 AVI workshop on BEyond time and errors: novel evaluation methods for information visualization (pp. 1-6).
-
Locoro, A., Cabitza, F., Actis-Grosso, R., & Batini, C. (2017). Static and interactive infographics in daily tasks: A value-in-use and quality of interaction user study. Computers in Human Behavior, 71, 240-257.
-
Bellino, A. (2015). Enhancing pinch-drag-flick paradigm with two new gestures: Two-finger-tap for tablets and tap\&tap for smartphones. In Human-Computer Interaction–INTERACT 2015: 15th IFIP TC 13 International Conference, Bamberg, Germany, September 14-18, 2015, Proceedings, Part III 15 (pp. 534-551). Springer International Publishing.
-
Hermann, T., Hunt, A., & Neuhoff, J. G. (2011). The sonification handbook (Vol. 1). Berlin: Logos Verlag.
-
Bellino, A., & Rocchesso, D. (2024, June). Controlling Trajectories with OneButton and Rhythm. In Proceedings of the 2024 International Conference on Advanced Visual Interfaces (pp. 1-3).
-
Beaudouin-Lafon, M., & Mackay, W. E. (2007). Prototyping tools and techniques. In The human-computer interaction handbook (pp. 1043-1066). CRC Press.
-
Dragicevic, P., Jansen, Y., & Vande Moere, A. (2020). Data physicalization. Handbook of human computer interaction, 1-51.
-
Bellino, A., & Herskovic, V. (2023, September). Protobject as a tool for teaching computational thinking to designers: student perceptions on usability. In Proceedings of the 15th Biannual Conference of the Italian SIGCHI Chapter (pp. 1-8).
-
Krumm, J. (Ed.). (2018). Ubiquitous computing fundamentals. CRC Press.
-
Rogers, Y. (2023). Interaction design: beyond human-computer interaction.
-
MediaPipe Solutions guide | Google AI Edge | Google AI for Developers
-
Gallery of Physical Visualizations and Related Artifacts (dataphys.org)